
In today’s data-driven world, efficient data pipelines have become the backbone of successful organizations. These pipelines ensure that data flows smoothly from various sources to its intended destinations, enabling businesses to make informed decisions and gain valuable insights. Two powerful tools that have emerged to simplify the management of data pipelines are DBT (Data Build Tool) and Airflow. These tools, when combined, form a dynamic duo that streamlines and scales data engineering workflows. In this blog, we will explore the benefits of using DBT and Airflow together and how they make data pipeline management easier than ever before. Whether you’re a data engineer or a business professional working with data, understanding the power of DBT and Airflow can greatly enhance your ability to leverage data effectively. So, let’s dive into the world of DBT and Airflow and discover how they revolutionize data pipelines.
In this blog, we will cover:
- Understanding DBT and Airflow
- What is DBT?
- What is Airflow?
- DBT and Airflow Integration Best Practices
- Scalability and Flexibility
- Hands-On
- Conclusion
Understanding DBT and Airflow
What is DBT?
DBT, which stands for Data Build Tool, is a powerful tool designed to transform and manage data in a scalable and reproducible manner. It allows data engineers to define and execute data transformations in a structured and modular way. Think of DBT as a toolkit that takes raw data and applies a series of predefined steps to make it clean, structured, and ready for analysis. With DBT, you can perform tasks like filtering, aggregating, joining, and validating data, ensuring its quality and accuracy.
What is Airflow?
Airflow is an open-source platform that helps manage and orchestrate complex data pipelines. It provides a way to define, schedule, and monitor workflows, ensuring that data moves seamlessly between various systems and processes. Airflow uses a graphical interface to design workflows, known as Directed Acyclic Graphs (DAGs), where each node represents a task or operation to be performed. These tasks can include data extraction, transformation, loading, and more. Airflow’s strength lies in its ability to handle dependencies, schedule tasks, and provide visibility into the pipeline’s progress.
By combining DBT and Airflow, you get the best of both worlds. DBT takes care of the data transformation aspect, while Airflow handles the orchestration and scheduling of these transformations. Together, they form a dynamic duo that simplifies and streamlines the entire data pipeline process. In the next section, we will delve deeper into the integration between DBT and Airflow, and explore how they work together synergistically to create efficient and scalable data pipelines.
DBT and Airflow Integration Best Practices

To make the most out of the DBT and Airflow integration, it’s important to follow some best practices. Firstly, ensure that you have set up the integration correctly by configuring the necessary connections and operators in Airflow. This typically involves defining the DBT transformation tasks within your Airflow DAGs and specifying the appropriate inputs and outputs.
Next, focus on managing dependencies and scheduling. Airflow provides various mechanisms to control task dependencies, such as triggering a task only when its upstream tasks have been completed successfully. Leverage these features to ensure that DBT transformations are executed in the correct order and with the required data available.
One of the key advantages of using DBT and Airflow together is the ability to monitor and log your data pipelines effectively. Both DBT and Airflow provide extensive logging and monitoring capabilities, allowing you to track the progress of your transformations and identify any issues or bottlenecks. Take advantage of these features to gain visibility into your pipeline’s health and performance.
By following these best practices, you can harness the full power of the DBT and Airflow integration. The combination of DBT’s data transformation capabilities and Airflow’s workflow orchestration ensures a seamless and efficient data pipeline management experience. In the next section, we will explore the advantages of using DBT and Airflow together in more detail, highlighting how they enhance data pipeline orchestration, reproducibility, testing, and scalability.
Scalability and Flexibility
- Scalability:
- Airflow’s distributed architecture allows for scaling data pipelines to handle large volumes of data.
- The workload can be distributed across multiple worker nodes, enabling parallel execution of tasks and reducing processing time.
- Scaling ensures data pipelines can accommodate increasing data volumes and growing business needs without sacrificing performance.
- Flexibility:
- DBT’s modular approach to data transformations offers flexibility in building and modifying pipelines.
- Transformations can be broken down into reusable DBT models, allowing easy customization based on specific requirements.
- Changes in data sources, business rules, or analytical needs can be quickly accommodated by adding or modifying DBT models.
- DBT’s flexibility facilitates collaboration among data teams, ensuring consistent and reliable transformations.|
- Collaborative Development:
- DBT’s modularity and version control capabilities promote collaboration among data teams.
- Teams can work on the same set of transformations, improving productivity and maintaining consistency.
- Code review, documentation, and sharing of best practices are facilitated within the organization.
Hands-On

To better understand how DBT and Airflow work together in practice, let’s consider a hands-on example. Imagine you’re working on a customer analytics project, where you need to transform raw customer data from various sources into a structured format for analysis. You can start by creating DBT models that define the necessary transformations, such as cleaning the data, aggregating customer metrics, and joining it with relevant reference data. Once your DBT models are defined, you can integrate them into an Airflow DAG. Within the DAG, you can schedule and orchestrate the execution of DBT transformations alongside other tasks, such as data extraction and loading. Airflow’s visual interface makes it easy to design and manage this DAG, allowing you to define the dependencies between tasks and set up scheduling intervals. With the integration in place, Airflow will trigger the DBT transformations at the designated times, ensuring that the data is processed and made available for further analysis. This practical implementation demonstrates how DBT and Airflow work seamlessly together, enabling you to build and manage sophisticated data pipelines efficiently.
- Install DBT and Airflow:
- Set up DBT:
- Create a new DBT project by running the command
dbt init <project name >in your terminal.
- Create a new DBT project by running the command

You can choose Snowflake or Postgres or any other database based on your installation.
- Navigate to the project directory using cd <project name > and configure your DBT profiles by editing the profiles.yml file. Provide the necessary connection details for your data sources and destinations.
Here, we have used this account for testing purposes, and in the same format, you can provide your connection details.

- Define DBT Models:
- Create DBT models in the model’s directory of your project. These models define the data transformations you want to apply to the customer data.
schema.yml file:
- Create DBT models in the model’s directory of your project. These models define the data transformations you want to apply to the customer data.

- Use SQL or the DBT-specific Jinja templating language to write the transformations. For example, you can create a model that cleans and aggregates customer data by grouping it by relevant attributes.
Here’s an example of defining an incremental model:
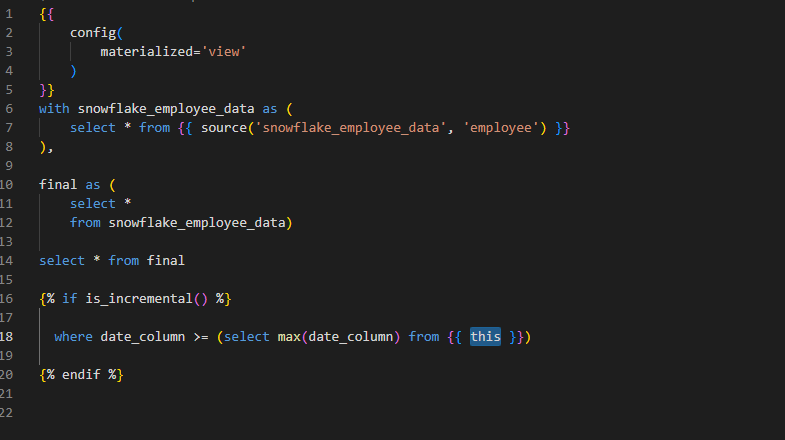
- Set up Airflow:
- Configure Airflow by editing the airflow.cfg file located in your Airflow installation directory. Customise settings such as the database connection and executor type. Or run your docker airflow image if you have installed it using docker.

- Initialize the Airflow metadata database by running airflow initdb in your terminal. For docker users, docker-compose up -d starts the airflow on the local host.
- Go to http://localhost:8080/home and sign in using the airflow username. You can see all the DAGs currently present.
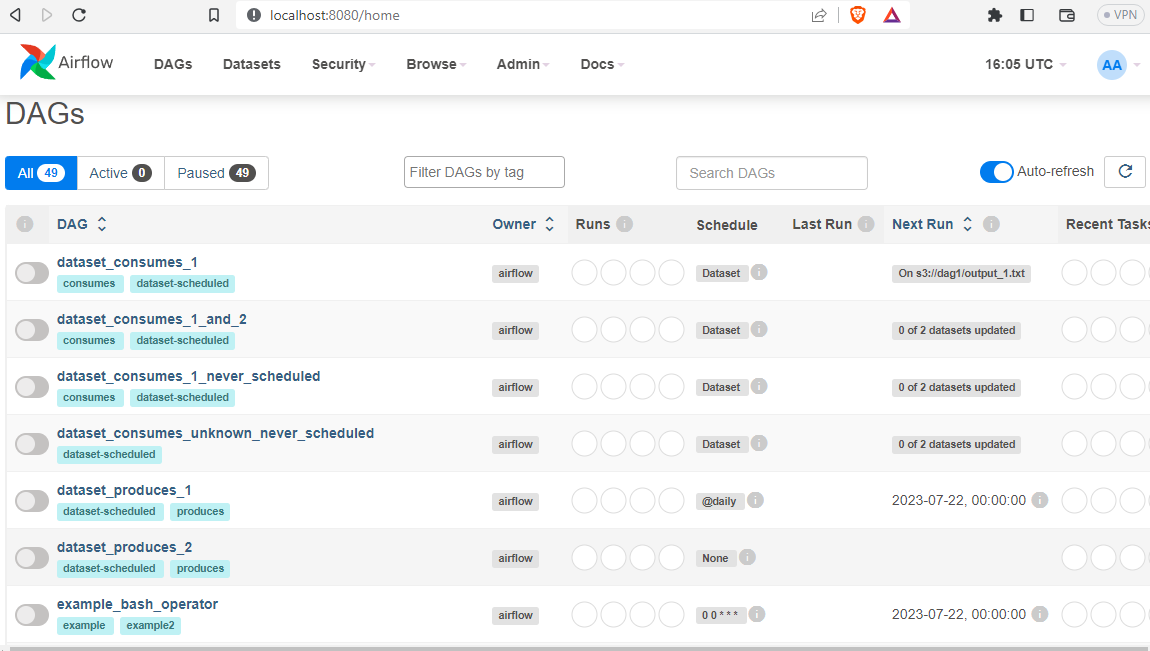
- Create an Airflow DAG:
- Define an Airflow DAG for your customer analytics pipeline. In the DAG, define the sequence of tasks, including DBT transformations, data extraction, and loading.
Creating an Airflow DAG with a DBTOperator to execute DBT transformations requires defining the DAG, the DBTOperator, and establishing the task dependencies. Below is an example Python script that demonstrates how to achieve this:
Import Necessary Libraries:
- Define an Airflow DAG for your customer analytics pipeline. In the DAG, define the sequence of tasks, including DBT transformations, data extraction, and loading.
Define default arguments for DAG:

Use the Airflow Python API or the Airflow web interface to create the DAG.
Specify the task dependencies and scheduling intervals for each task.
Define the dag instances, and dependencies based on your requirements:

- Integrate DBT in Airflow:
- Within the DAG, add a DBTOperator to execute the DBT transformations. Set the necessary parameters such as the path to your DBT project directory and the specific models to run.
- Define the dependencies between the DBT task and other tasks in the DAG to ensure the transformations run in the correct order.
- Start Airflow Scheduler and Web Server:
- Start the Airflow Scheduler by running airflow scheduler in your terminal. This scheduler will trigger the tasks according to the defined schedule.
- Start the Airflow Web Server by running airflow webserver in a separate terminal. The web server provides a graphical interface to monitor and manage your DAGs.
- Monitor and Test:
- Access the Airflow web interface and navigate to the DAG you created. Monitor the progress of the tasks and ensure the DBT transformations are executed successfully.
- Validate the output of the pipeline by analyzing the transformed customer data or loading it into a data warehouse for further analysis.
Conclusion
In this blog, we demonstrated how DBT’s data transformation capabilities and Airflow’s workflow orchestration, can enhance the efficiency and scalability of your data pipelines, ultimately enabling you to unlock the full potential of your data. As the data landscape continues to evolve, having a solid foundation in managing data pipelines is crucial for driving informed decision-making and gaining a competitive edge. We will come up with more such use cases in our upcoming blogs.
Meanwhile…
If you are an aspiring Data enthusiast and want to explore more about the above topics, here are a few of our blogs for your reference:
- How to Use DBT to Get Actionable Insights from Data?
- How to Master Data Transformations with DBT Materializations?
Stay tuned to get all the updates about our upcoming blogs on the cloud and the latest technologies.
Keep Exploring -> Keep Learning -> Keep Mastering
At Workfall, we strive to provide the best tech and pay opportunities to kickass coders around the world. If you’re looking to work with global clients, build cutting-edge products, and make big bucks doing so, give it a shot at workfall.com/partner today!


