
2.5 quintillion bytes of data are produced every day with 90% of it generated solely in the last 2 years (Source: Forbes). Data is pulled, cleaned, transfigured & then presented for analytical purposes & put to use in thousands of applications to fulfill consumer needs & more.
While generating insights from the data is important, extracting, transforming, and loading the same data is equally important. As the data is growing day by day it becomes a crucial part of an organization to store, migrate, and load the data in an efficient manner.
In this blog, we will demonstrate how we can read the data from an API source, do some transformations and load the same data as a CSV file to an Amazon S3 bucket. Also how we can make use of this transformed data on the S3 bucket to connect it to PowerBI which is a data visualization tool and actually perform some data analysis?
In this blog, we will cover:
- What is ETL?
- What is Airflow?
- Amazon S3 Bucket
- Hands-on
- Conclusion
What is ETL?
ETL extract for Extract Transform and Load. It is used to collect data from a variety of sources like flat files, API data, vendor data, etc while doing some transformations in the middle which includes de-duplication or mapping, and this transformed data gets loaded in data storage.
In our example this would be the ETL architecture :
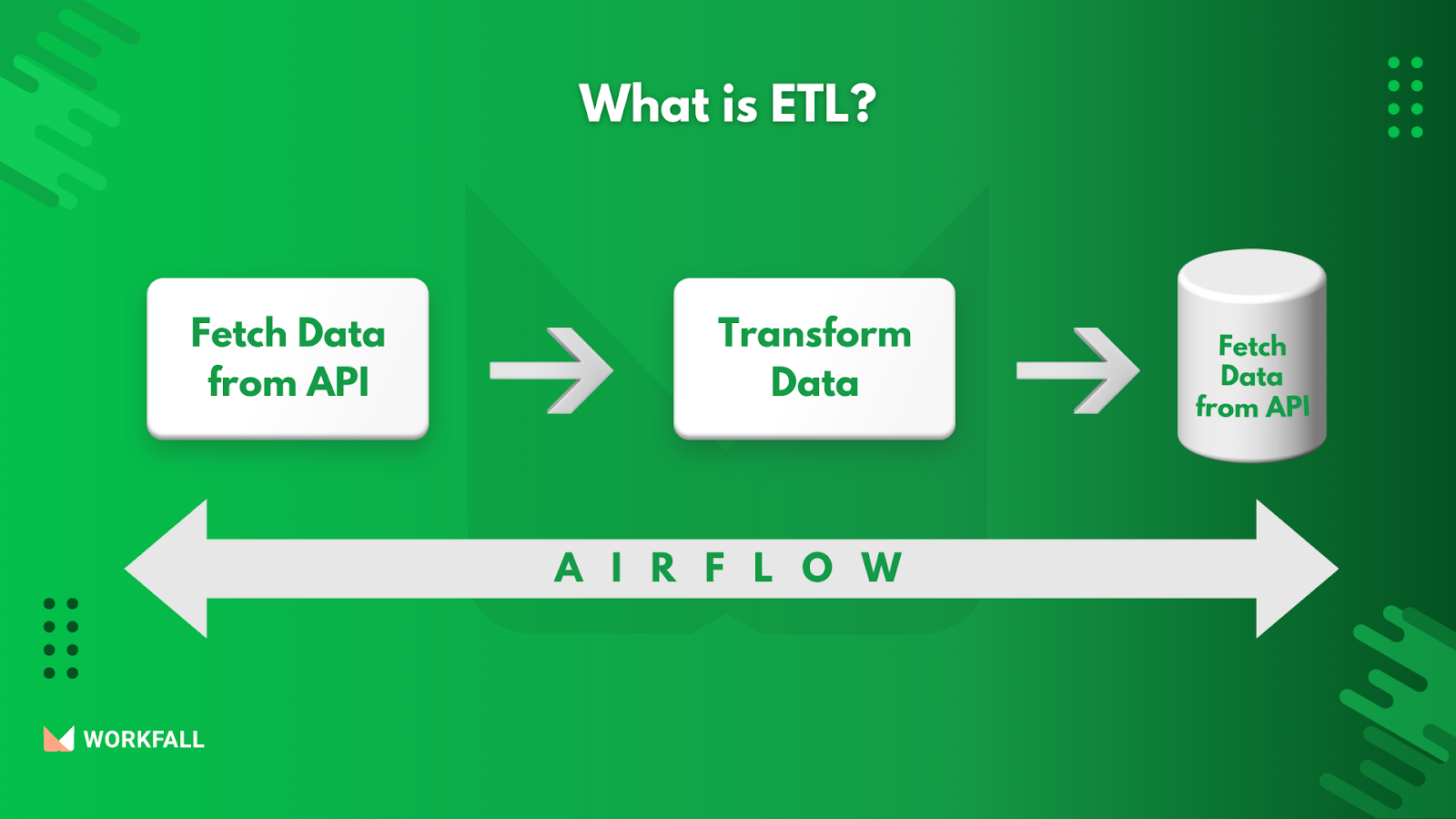
- Extract Operation: Fetching of data from the API endpoint
- Transformation Operation: Transforming the dataset by removing unnecessary columns
- Loading Operation: Loading the transformed data to the AWS S3 bucket
What is Airflow?
Apache Airflow is an open-source workflow management platform used for creating, scheduling, and monitoring workflows or data pipelines by writing code. Airflow is written in Python and is used to create a workflow.
Workflow is a sequence of tasks/work that are started or scheduled or triggered by an event. Airflow makes use of Directed Acyclic Graph (DAGs) in such a way that these tasks can be executed independently.
To set up Airflow and know more about it, you can check out this blog:
How to easily build ETL Pipeline using Python and Airflow?
Amazon S3 bucket
S3 stands for Simple Storage Device and is used to store the data as object-based storage. S3 also provides us with unlimited storage and we don’t need to worry about the underlying infrastructure.
Hands-on
To create your first Amazon S3 bucket, you can follow the steps here:
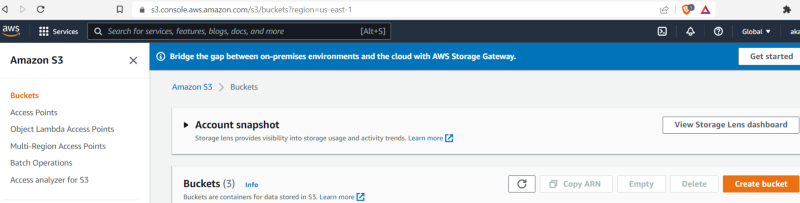
1. Log in to the AWS and in the management console search for S3
2. Select the AWS S3 Scalable storage in the cloud.

3. In the S3 management console, click on Create Bucket.
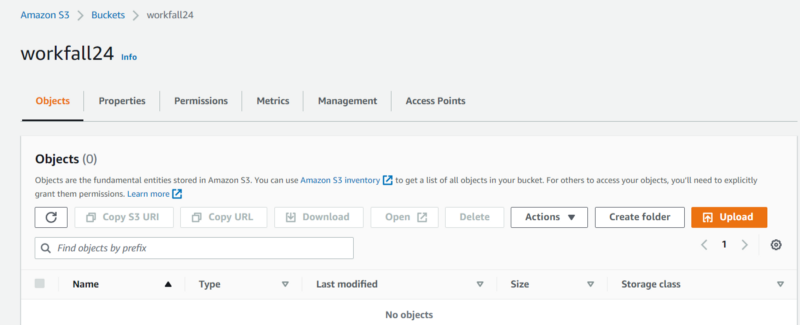
4. Enter a unique bucket name following the chosen region and create a bucket.
This would successfully create a bucket and you can configure other details accordingly.
Fetching data from API source
The data which we would be using for ETL would be Stackoverflow API which can be found here: api.stackexchange.com.

We would extract the data for “ What are the top trending tags appearing in StackOverflow this month?”The API for getting the question answered can be found here:
api.stackexchange.com/2.3/tags?order=desc&a..
The API endpoint result :

For simplification, we have taken this API as it has a very less volume of data present. You can also look for any such free APIs and it does not require any access keys or credentials.
This data would be further transformed using pandas and we shall see it in the next few steps.
Write Airflow DAG in python to create a data pipeline
Steps to create the airflow DAG in python :
- Fetching the data from the StackOverflow API endpoint.
- Transforming the data using Pandas
- Loading the data to the Amazon S3 bucket
Fetching the data from the StackOverflow API endpoint
The first step would be to load the required libraries in the python file :

Create a function get_stackoverflow_data() and get the data using the requests library

In the code snippet, ti stands for task instance and it is used to call xcoms_push and xcoms_pull. XComs stands for cross-communication which is a mechanism where tasks communicate with each other. They can only pass small amounts of data or API requests.
xcom_push is used to push the data to task storage on the task instance.
xcom_pull is used to pull the data from task storage on the task instance.
The next step would be to transform this data. We would be removing the unnecessary columns as the transformation step :

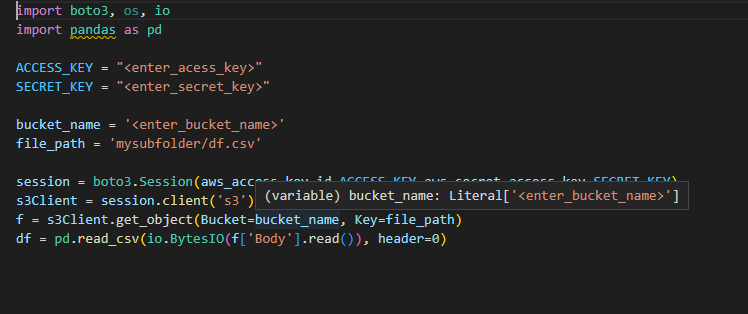
The final step would be to load this data in the AWS S3 bucket and for that, we would be using the boto3 library in python. We would also need the AWS access and secret keys that could be found in your AWS account and then would load this transformed data to S3 as a CSV file.
BOTO3 library is the python SDK for Amazon Web Services which allows us to read, create, delete and update AWS resources from python code.
How to use BOTO3?
- Import the library and indicate which service you would use.
S3_obj = boto3.resource(‘s3’) - Once we have resources, we can send or receive the requests like fetching, creating, or deleting buckets.
- We can also upload and download any file. In this example, we would be creating a temporary file object and putting our data in it and would upload that file as CSV on s3.
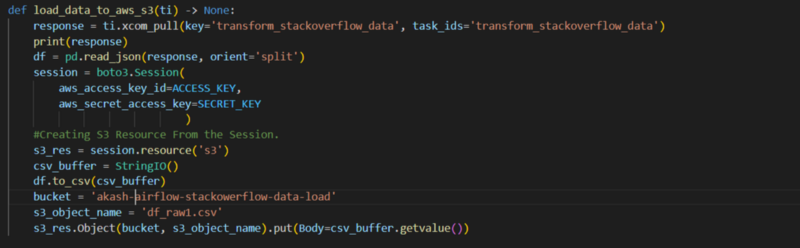
It is a good practice not to expose your AWS Access and Secret keys and access them by putting them in a private script, in this case, auth module.
Now all we need to do is to write DAGs, call these functions and define task dependencies and these can be achieved by the below steps:
There are three components of a DAG.
1- DAG Config: This is a dictionary where all the default properties of a DAG are defined like an owner, retries, retries_daily, etc.

2- DAG Instance: This is the part where all the basic properties of a DAG are defined. For example, description, schedule interval, dag_id, start_date, etc. It is used with the DAG function imported from the airflow module in the script.
3- DAG Tasks and Dependencies: This is the place where the tasks are created using Operators ( a templatized structure that is present as python classes and we can use these operators to create data tasks) which call the relevant functions associated with them.
The dependencies are set using “>>” operators. For example,
task1 >> task2 indicates that first task 1 will be completed and only then task2 will get started.
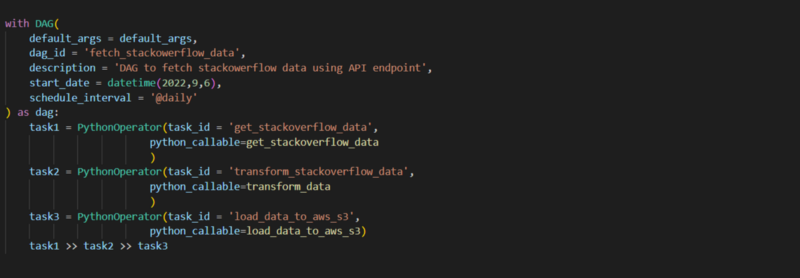
Airflow Data Pipeline DAG
After coding the data pipeline through python, go to the localhost where the Airflow UI is running. Log in and search for the created Dag.
Now, trigger the pipeline run.
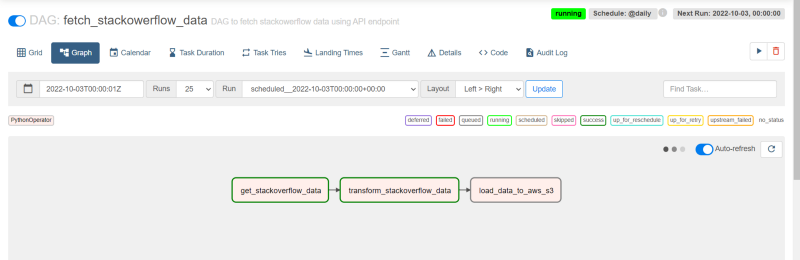
After a while, you should see all the tasks showing a dark green edge indicating that the DAG run was a success and all our tasks have been completed.
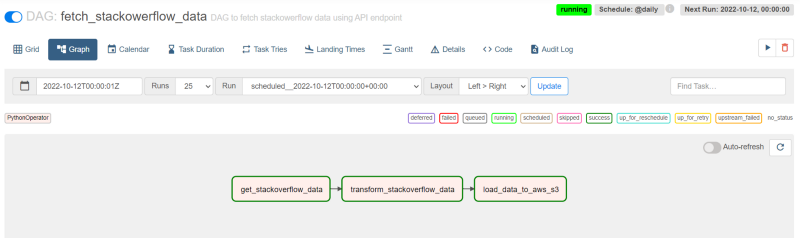
Validating the Data on AWS S3
The final step would now be to validate this data on Amazon S3 and see if we are able to see the CSV file in the bucket or not.
For that, open the S3 bucket and view the contents :

We can also see the file details and download the same :
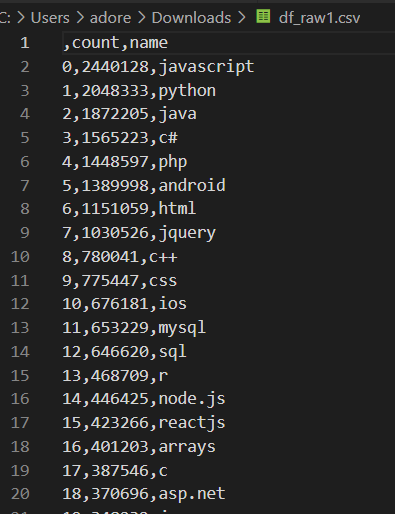
Connect S3 object with Power BI
We can make use of this data from AWS S3 and create a dashboard using a data visualization tool like powerbi.
- Open the Powerbi desktop application and go to Get Data -> Others -> Python Script
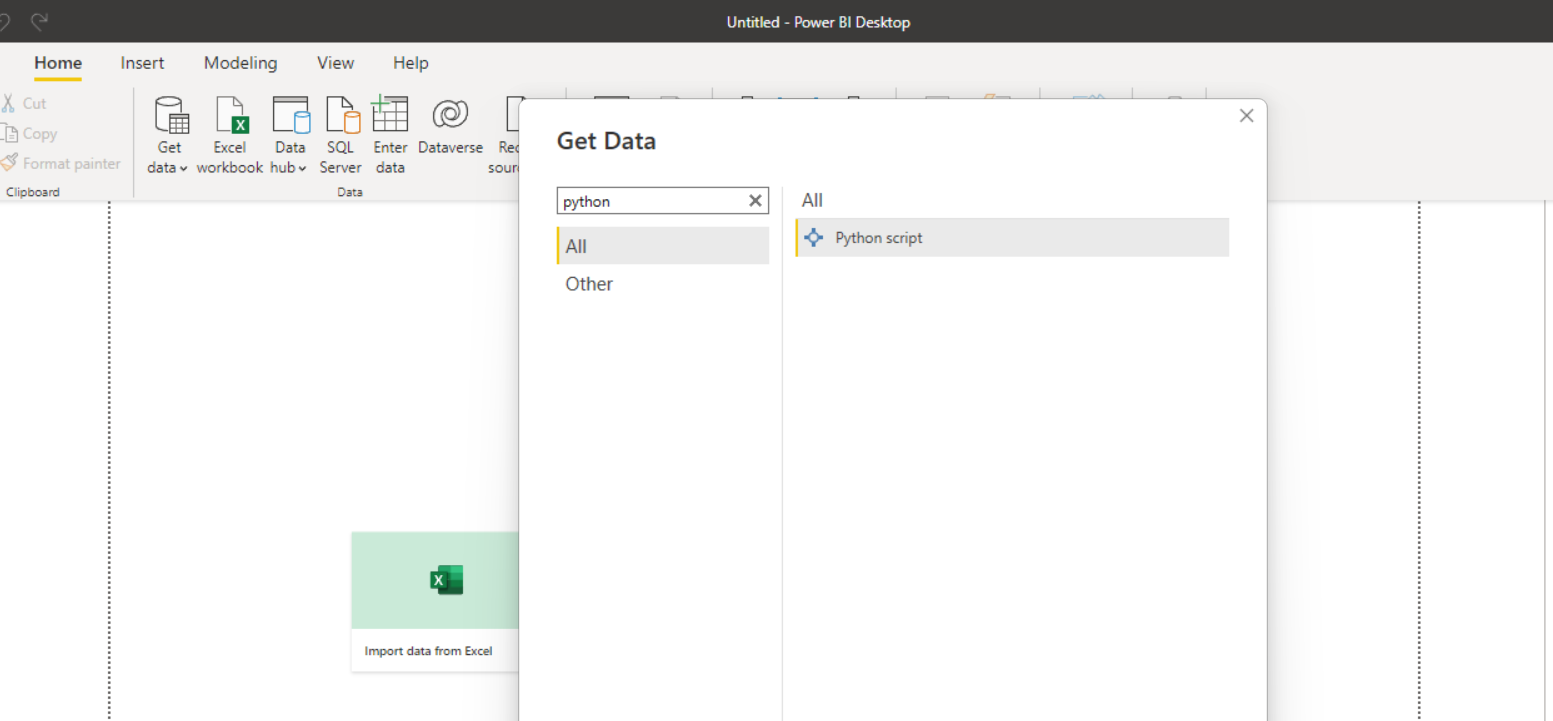
- Insert the code in the snippet in the editor
- Click OK and this CSV data will come as a data table.
- Now you can use this data for visualization using Powerbi as well and answer some questions like in the snapshot below:


This could answer questions like “Which tag was searched more than a million times? ” etc.
Conclusion
Airflow basically simplifies the creation of data pipelines and is widely used in the software industry for orchestrating ETL (Extract Load Transform) operations. With this blog, you would be able to extract the data from API and load it to cloud storage, and use the transformed data for further analysis. Once the data is on the cloud, it could be used for a wide range of applications like visualization, analytics in a data warehouse, etc. We will come up with more such use cases in our upcoming blogs.
Meanwhile…
If you are an aspiring AWS Enthusiast and want to explore more about the above topics, here are a few of our blogs for your reference:
- How to easily build ETL Pipeline using Python and Airflow?
- How to fetch contents of JSON files stored in Amazon S3 using Express.js and AWS SDK?
- How to enable MFA delete for S3 buckets?
Keep Exploring -> Keep Learning -> Keep Mastering
At Workfall, we strive to provide the best tech and pay opportunities to kickass coders around the world. If you’re looking to work with global clients, build cutting-edge products and make big bucks doing so, give it a shot at workfall.com/partner today!


