
In our previous blog, How to collect, aggregate and analyze Financial Services Industry (FSI)’s data on a petabyte scale using AWS FinSpace(Part 1)?
We have discussed FSI and Amazon FinSpace as data management and analytics platform designed specifically for the FSI. We have also discussed FinSpace features, benefits, how it works, pricing, etc., and how it reduces the time it takes FSI organizations to find, prepare, and analyze financial data from months to minutes. Refer to the following image for a quick recap:
In this blog, we will explore the Amazon FinSpace dashboard by creating an environment.
Hands-On
In this hands-on, we will see how we can create and make use of the Amazon FinSpace environment to simplify the process of Data Management and Analytics for prediction models.
In this hands-on we will be exploring the FinSpace dashboard and will create a new User Group, will add users to the user group, attach multiple permissions and thus, add a new dataset.
Finally, after attaching the required permissions and defining the schema for your dataset, we will then analyze the dataset on notebook on the Amazon SageMaker Studio console by integrating the FinSpace environment to the Amazon SageMaker Studio console and thereby accessing the data from the dataset for further analysis.
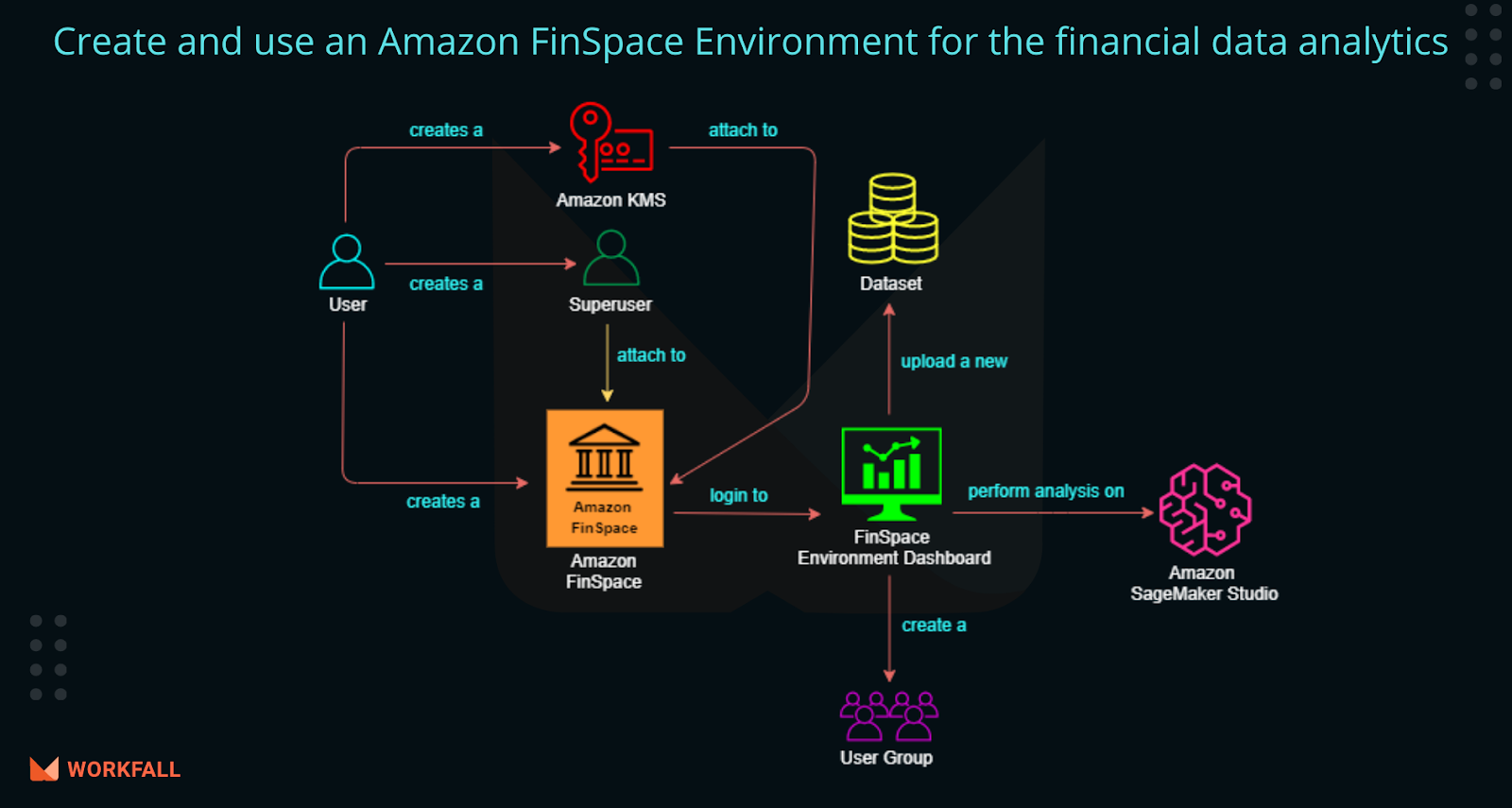
To implement this, we will do the following:
- Login to your AWS console and look for the Amazon FinSpace service.
- Select your preferred region based on the availability of service in that region.
- Navigate to the Amazon FinSpace dashboard and create a new environment.
- Create a new KMS key or select the default key if already created.
- Attach the KMS key to your newly created environment.
- Add a Superuser for your newly created environment.
- Note down the Temporary password.
- Navigate to the newly created environment domain and use the email address and temporary password to log in to your dashboard.
- Set a new password for your FinSpace environment.
- Create a new User Group in your FinSpace environment.
- Attach the required permissions for the User Group and add the users to the group.
- Upload a new dataset to your FinSpace environment.
- Edit your schema based on your dataset.
- Analyze the created dataset in a notebook on the Amazon SageMaker Studio console.
- Connect your FinSpace environment to your notebook.
- Analyze your dataset as per your requirements easily and efficiently to perform any type of prediction analysis.
Login to your AWS console and navigate to the dashboard.
Search for Amazon Finspace service and click on it.
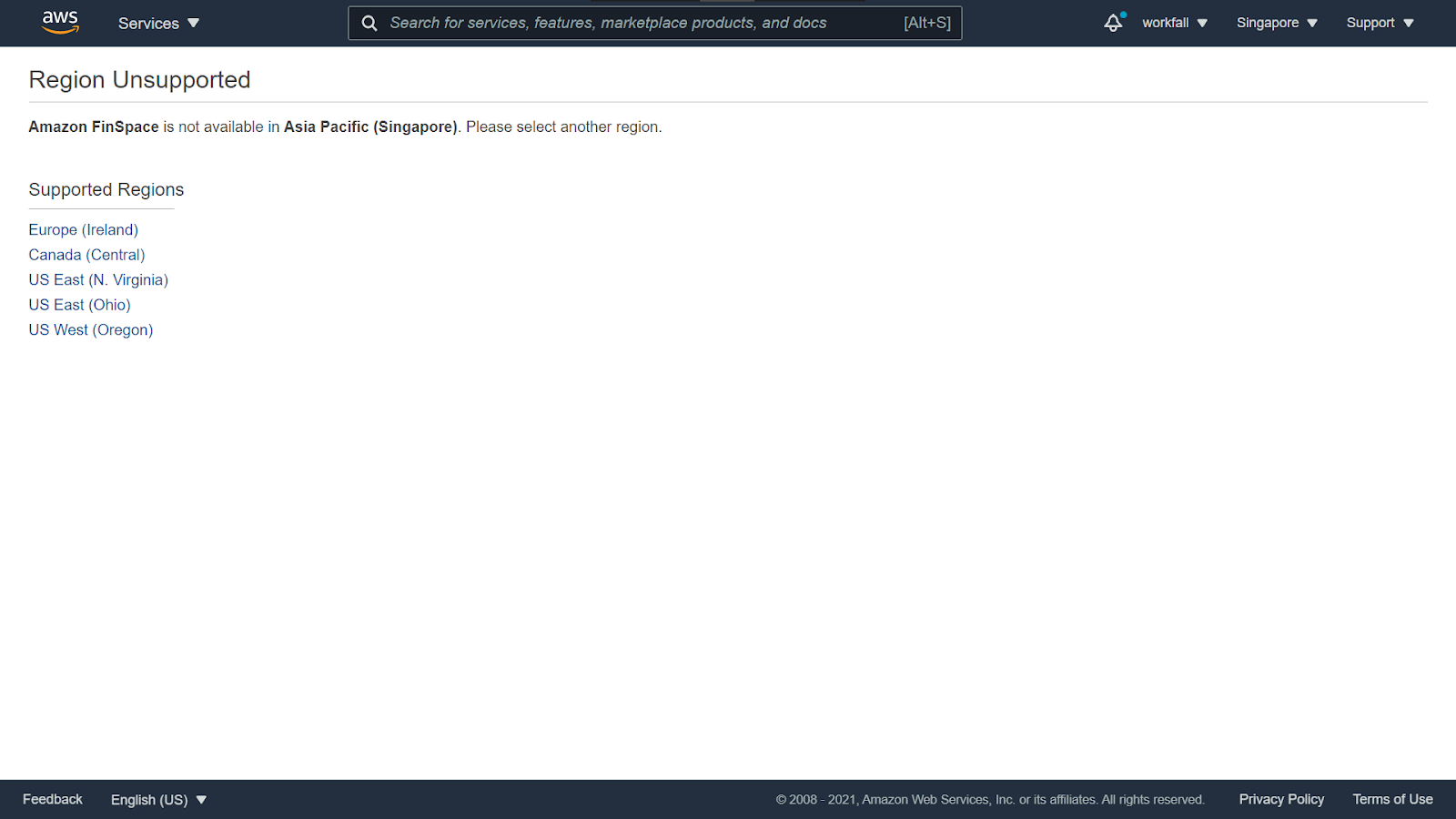
If the selected region is not available for a service, then choose some other region from the list of available regions.
You will be navigated to the Amazon FinSpace service dashboard. Click on Create environment.

You will be navigated to the Create Environment dashboard.
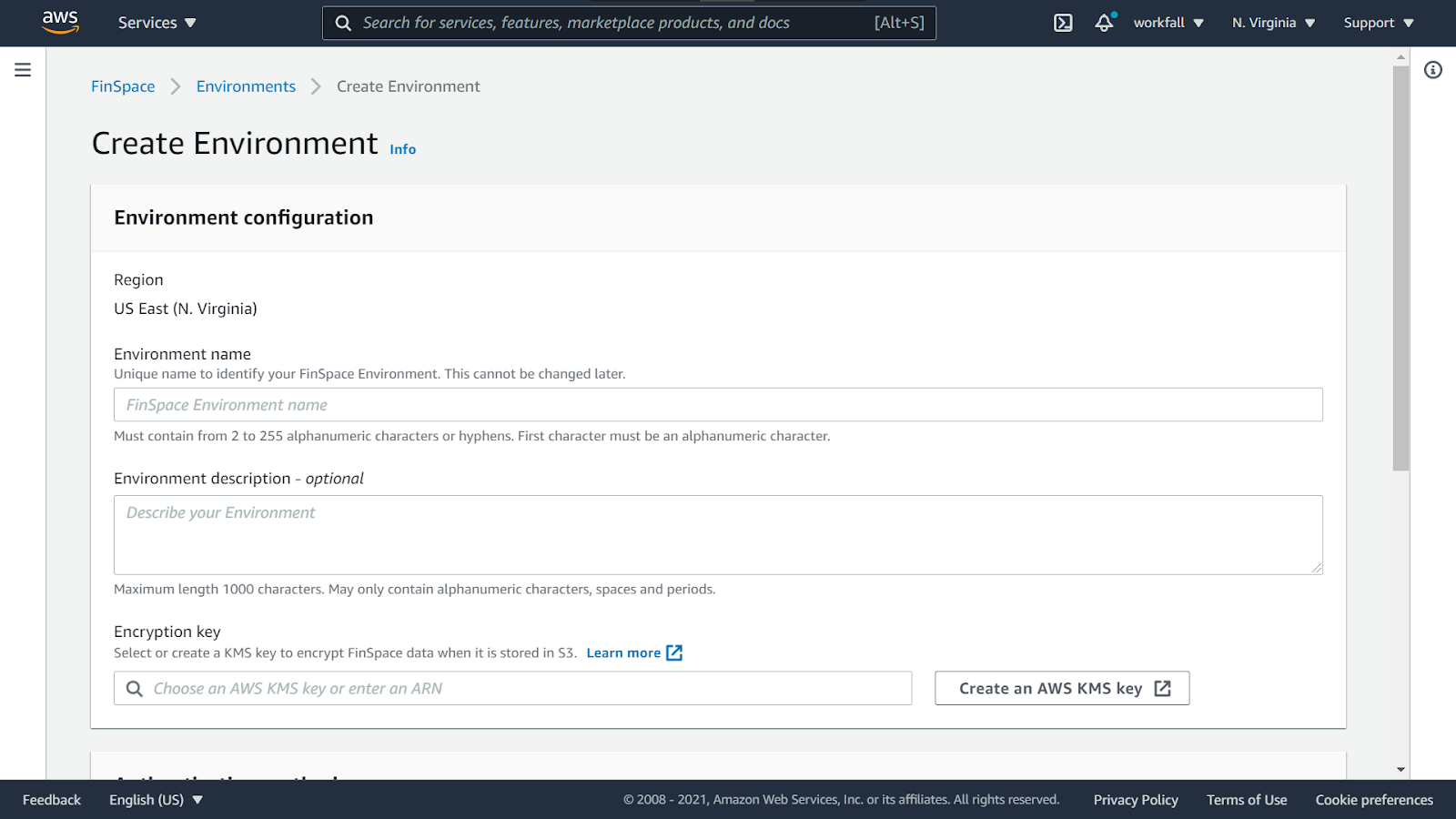
Enter an environment name and a description if needed.

Now, select a KMS key if you have one already created. If not, create a new KMS key. Click on Create an AWS KMS key.
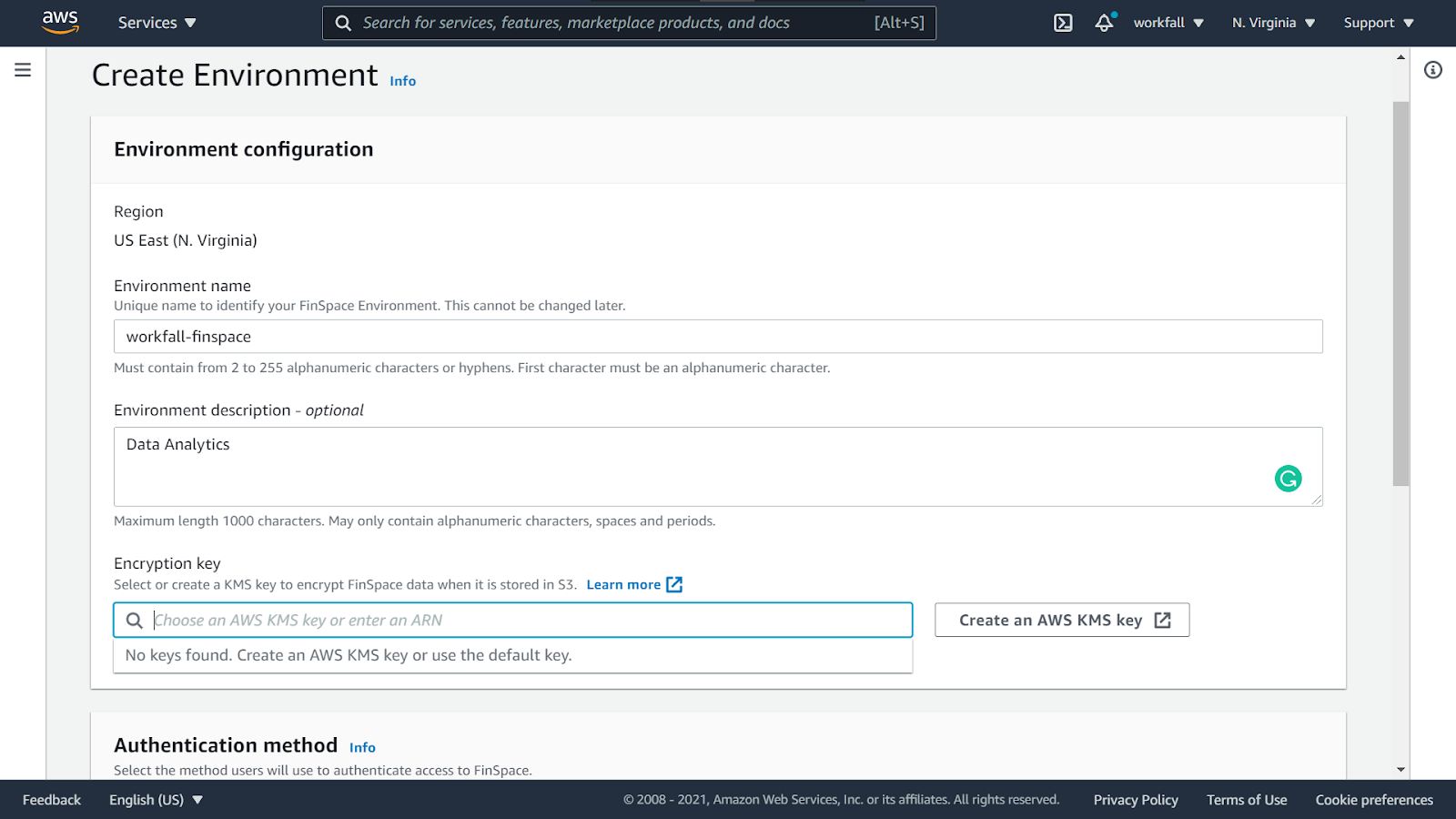
Select Symmetric and click on Next.

Enter an Alias, a description and a tag if needed.
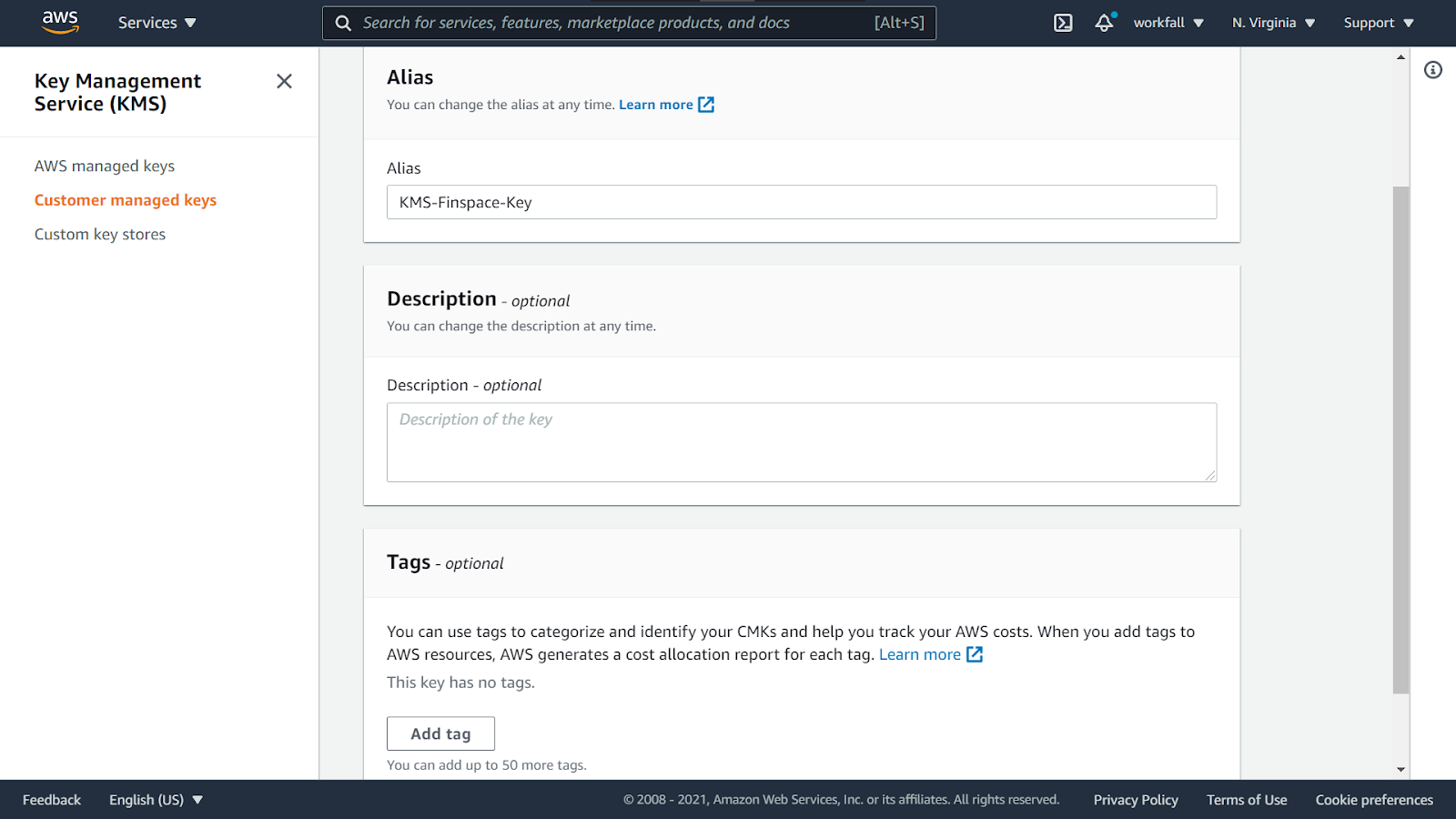
Scroll down and select Key administrators. Click on Next.

Select the accounts that should have access to the KMS key.
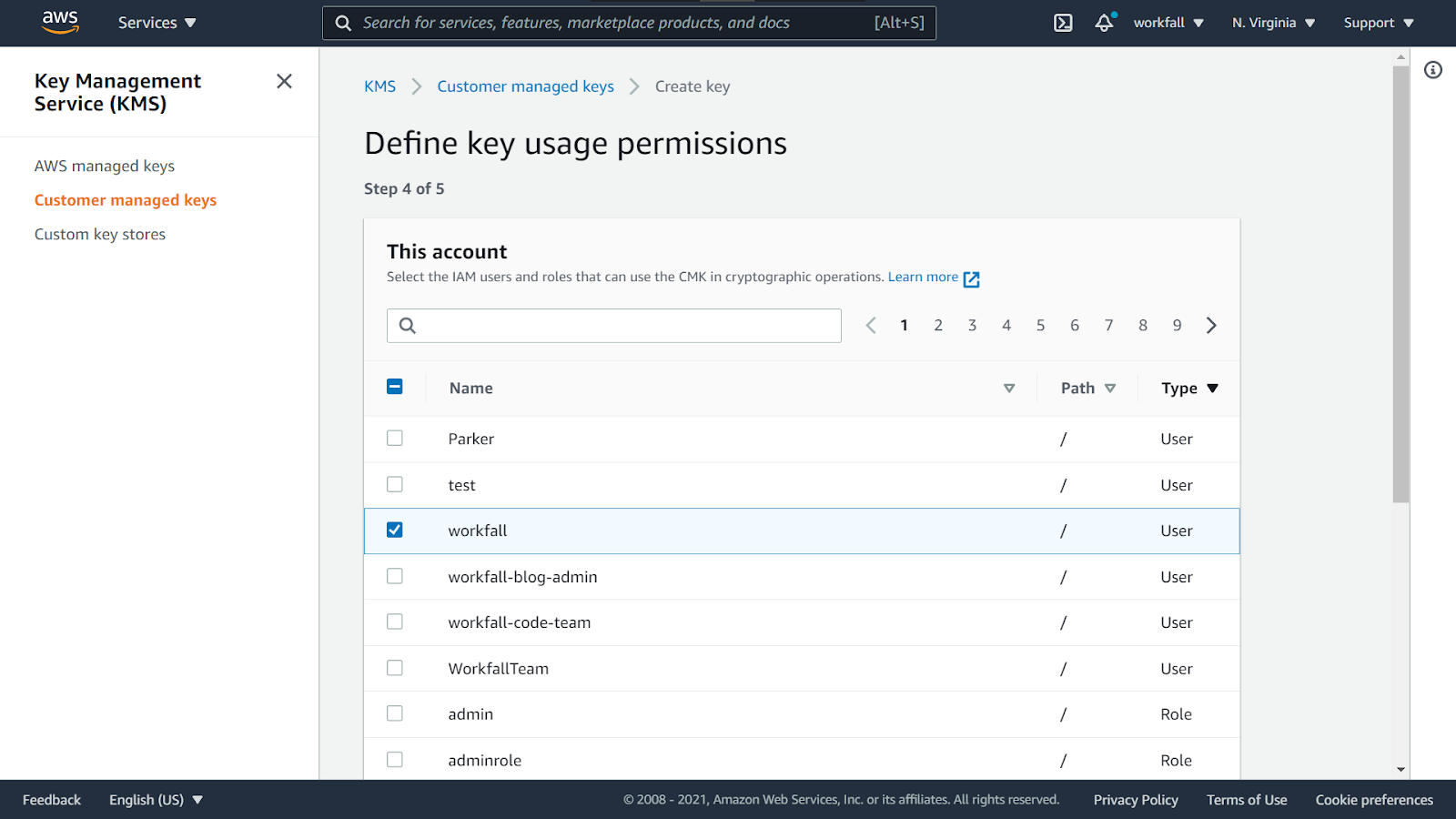
Cross verify the Key Policy and click on Finish.
On success, you will see a message as shown in the image below.
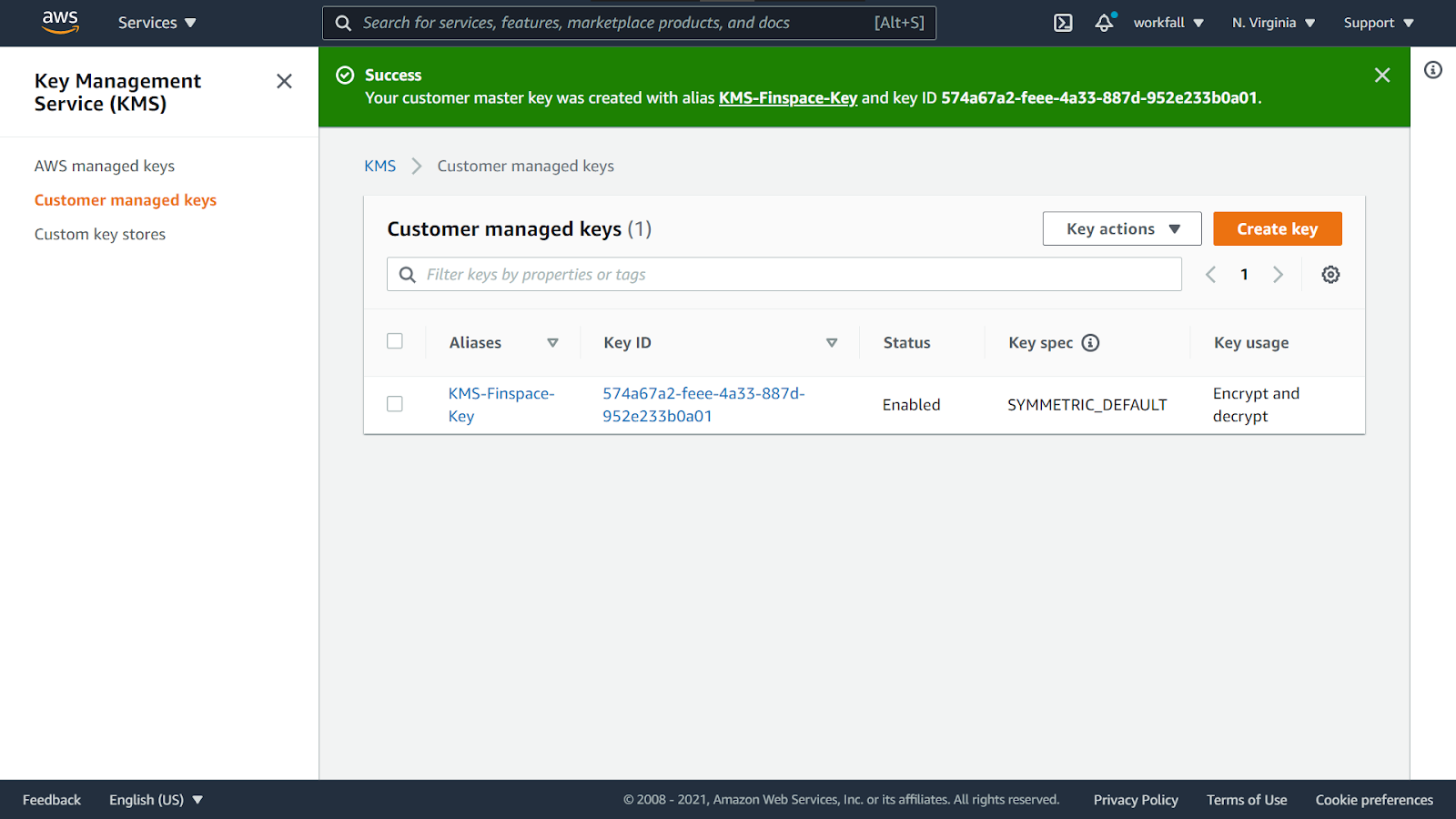
Navigate back to the Create Environment dashboard. Select the newly created KMS key.

You can verify the KMS key selected after selecting the same from the dropdown.
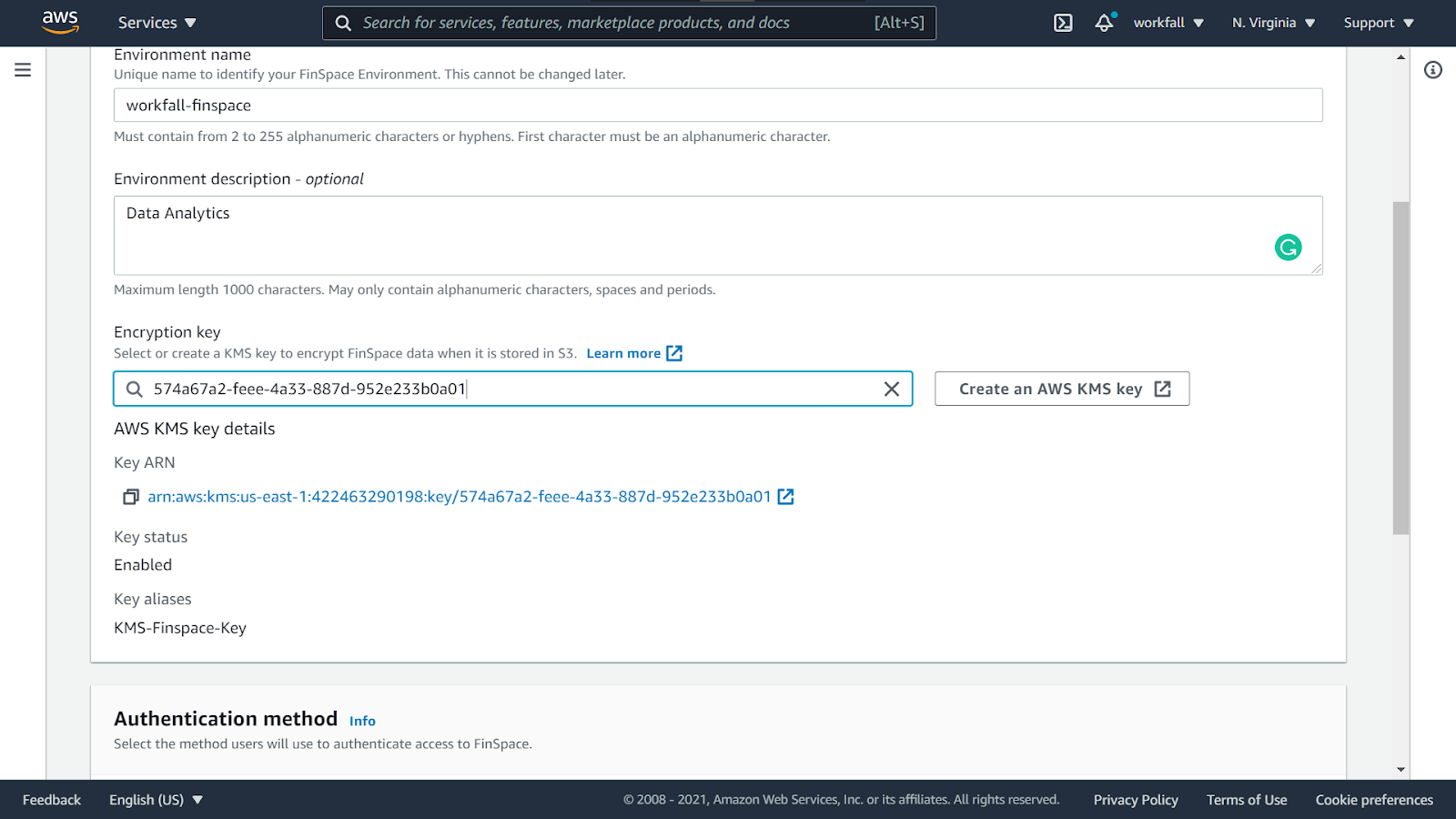
Select the Authentication method as Email and password.
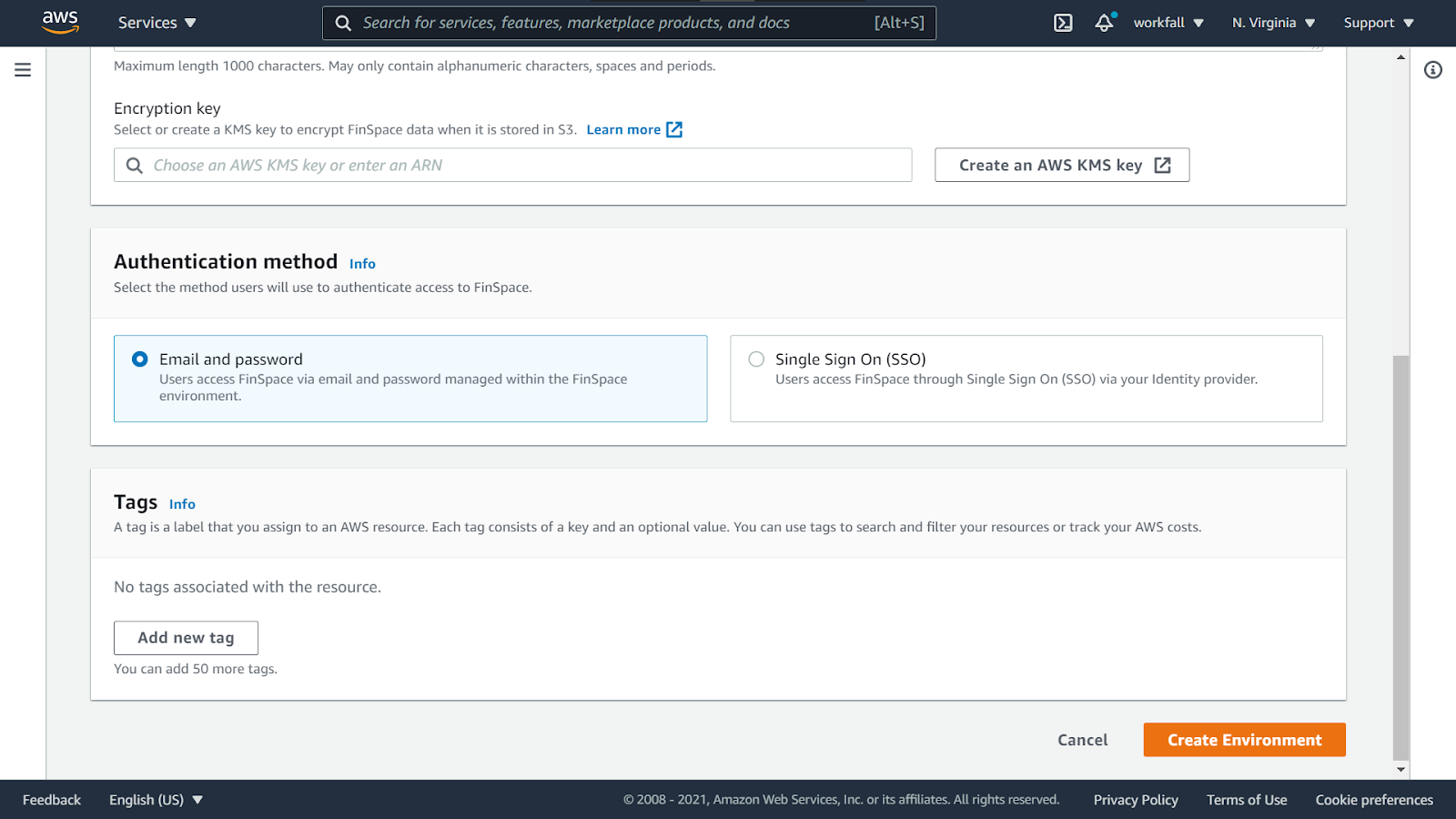
Add a tag for your environment. One done, click on Create Environment.
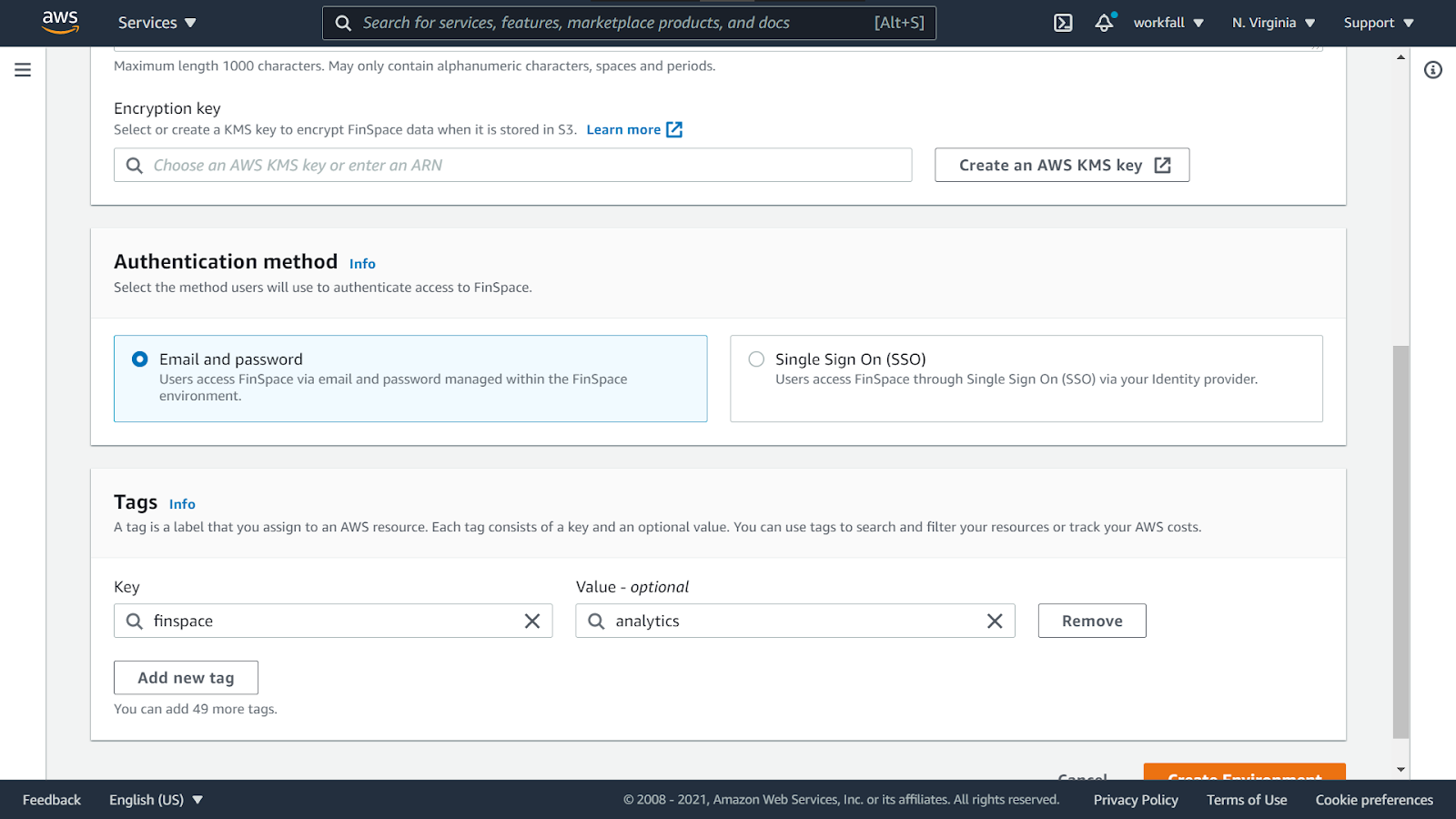
On success, your environment will begin the process of creation. It might take an hour for your environment to be created.

If you scroll down, you will see the sample data provided by FinSpace that you can load to your environment for testing purposes.
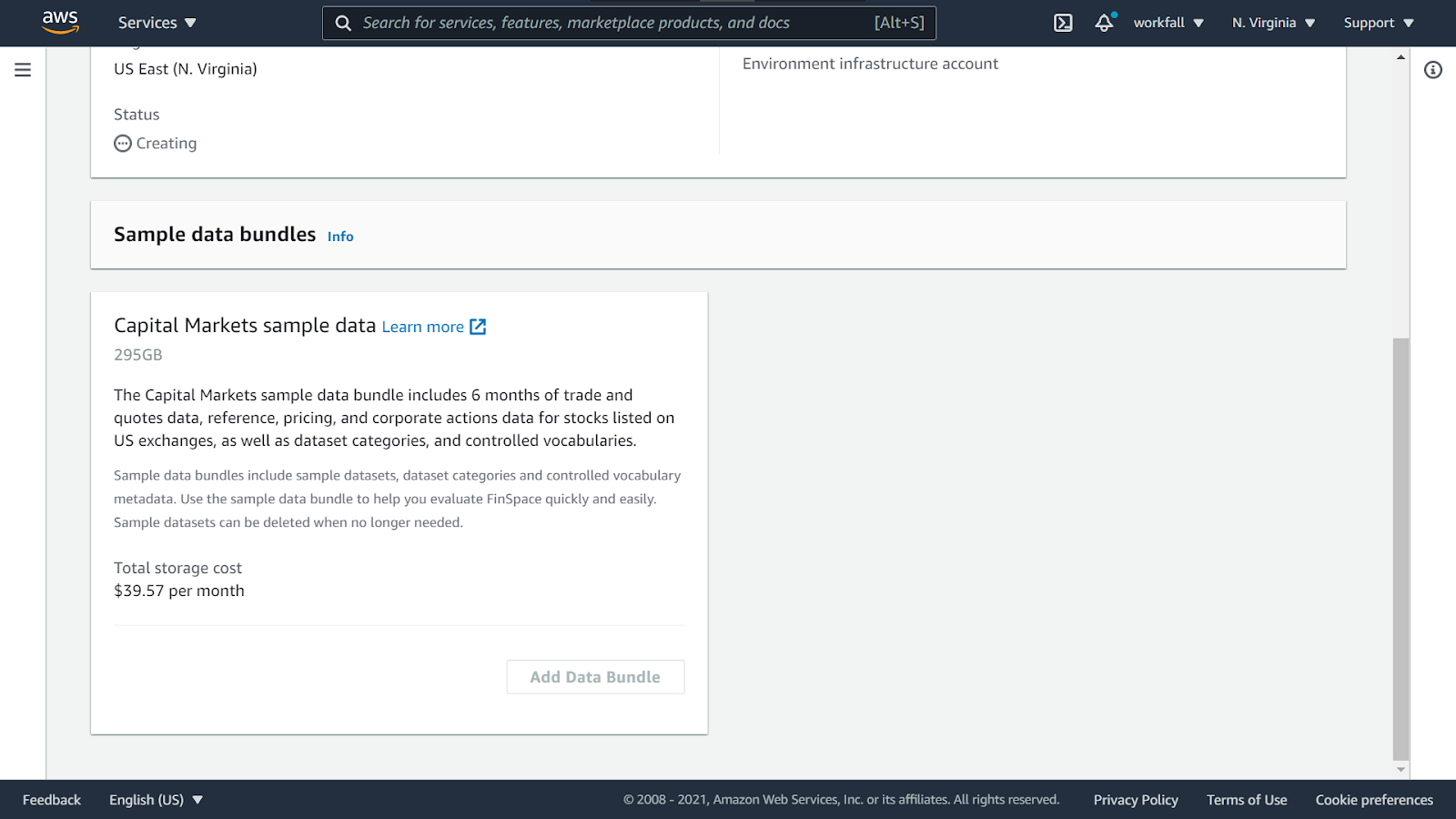
On successful creation of the environment, you will see the message as shown in the image below.

Scroll down and click on Add Superuser.

You will be navigated to the user creation dashboard.

Enter the email address, first name and last name and click on Next.
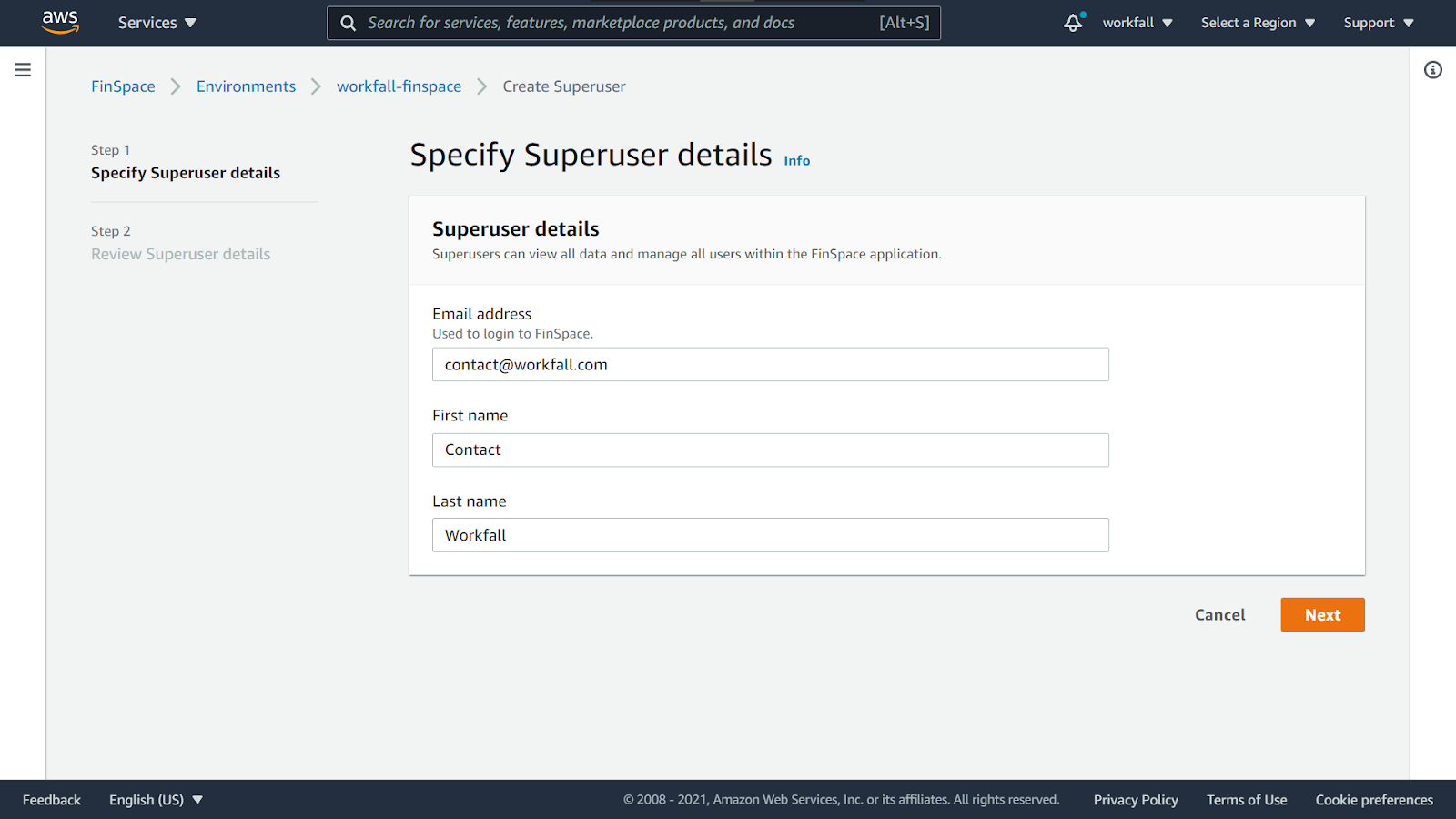
Verify the details and click on Create and view credentials.

On successful creation, you will see the screen as shown in the image below.

Scroll down and make a note of the temporary password. Click on Done.
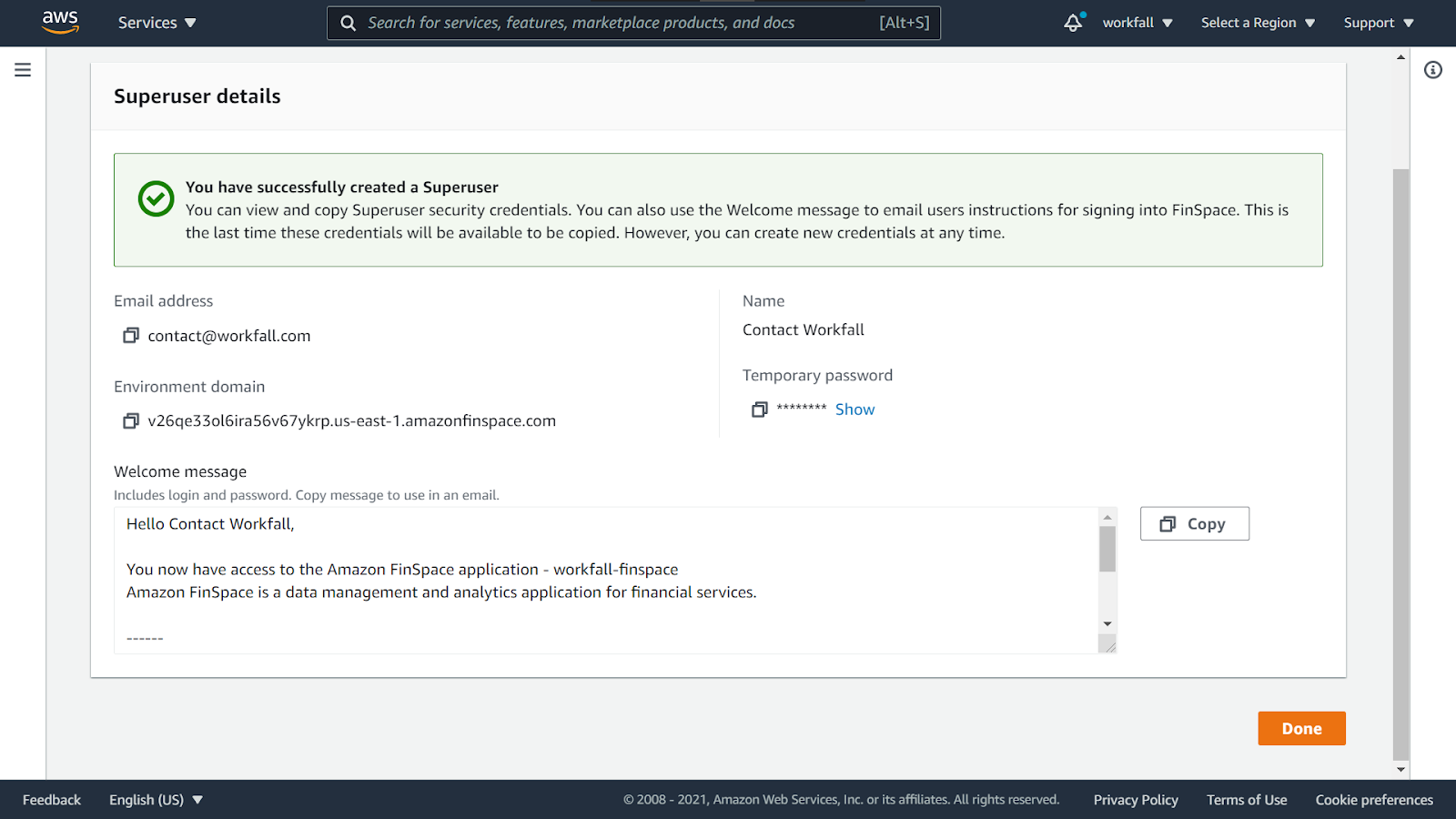
Now, click on the Environment domain to navigate to the FinSpace environment.
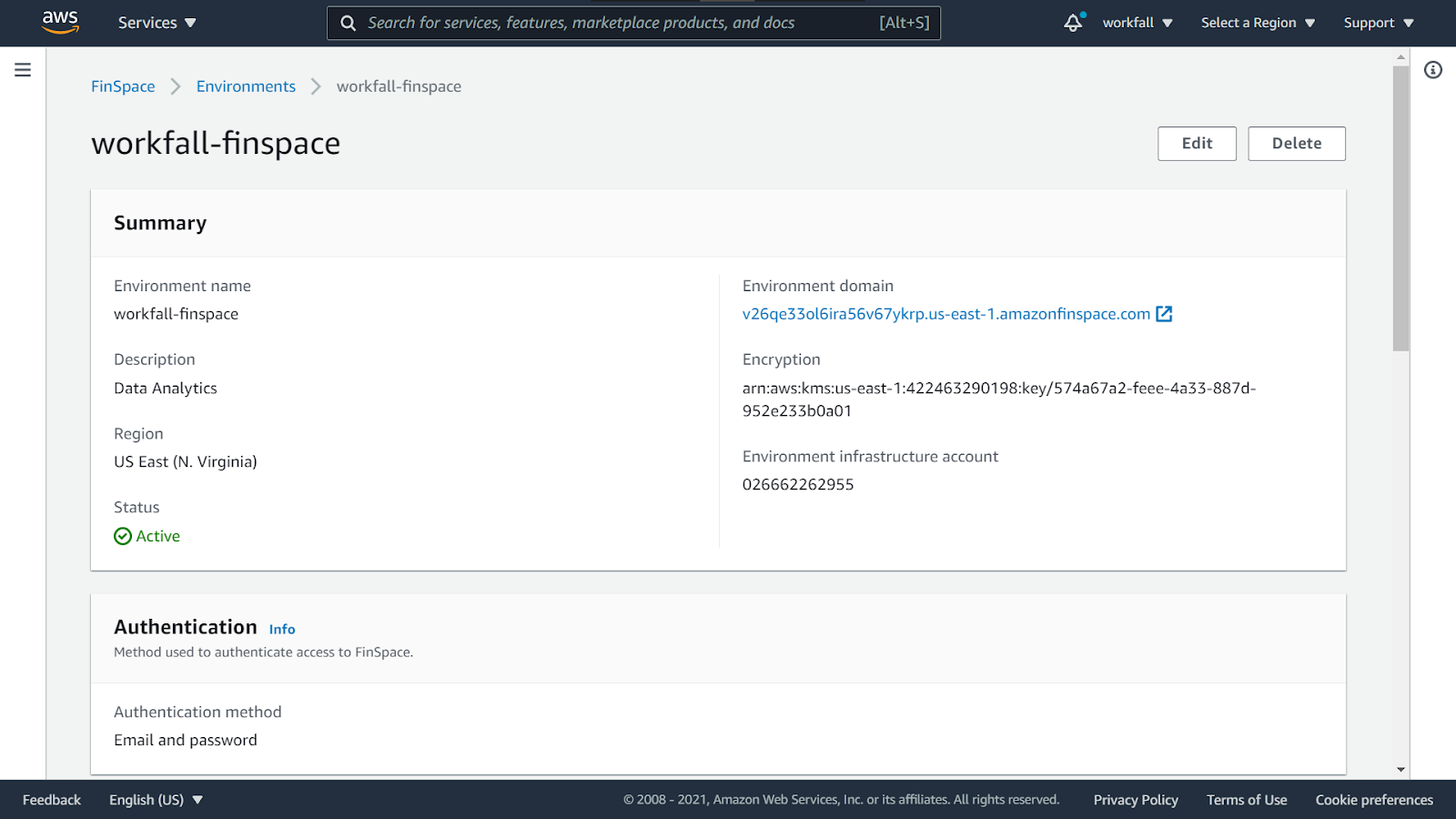
Enter in the email and the temporary password to sign in.

Enter a new password for your account and click on Send.
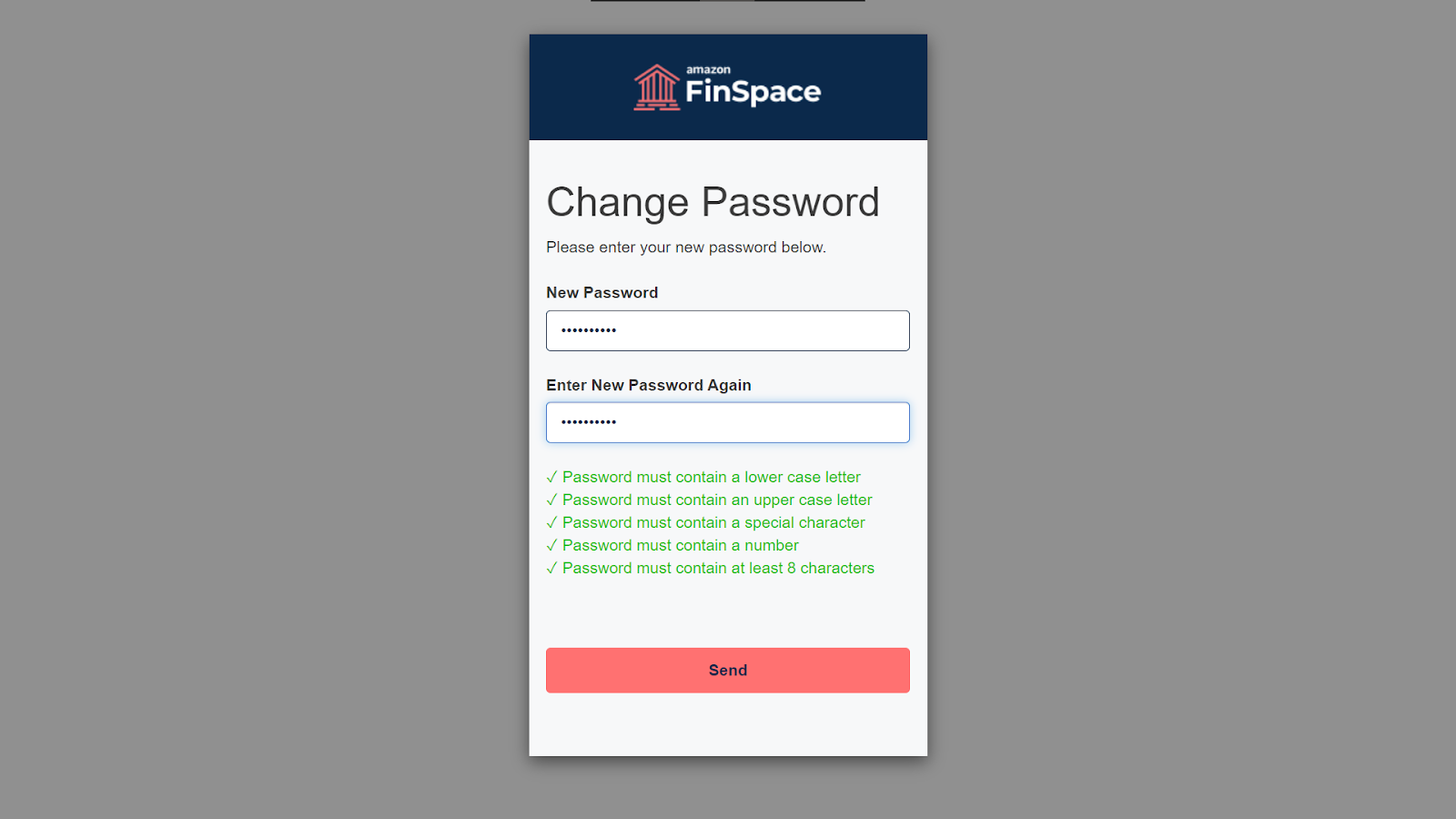
On success, you will be navigated to the homepage.

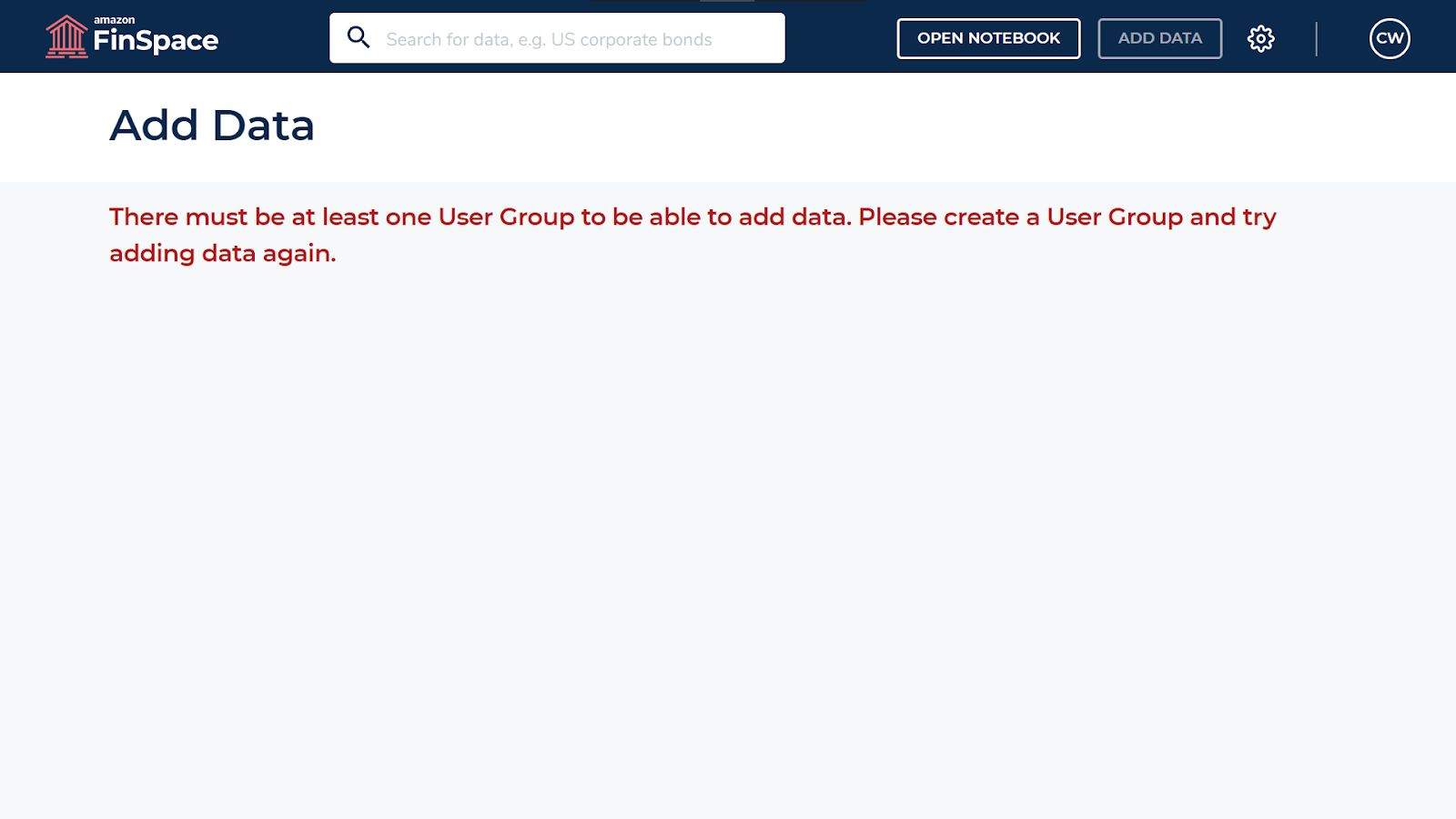
If you click on Add data, you will see the message as shown in the image below.
Click on the Settings icon and select Users and Groups.
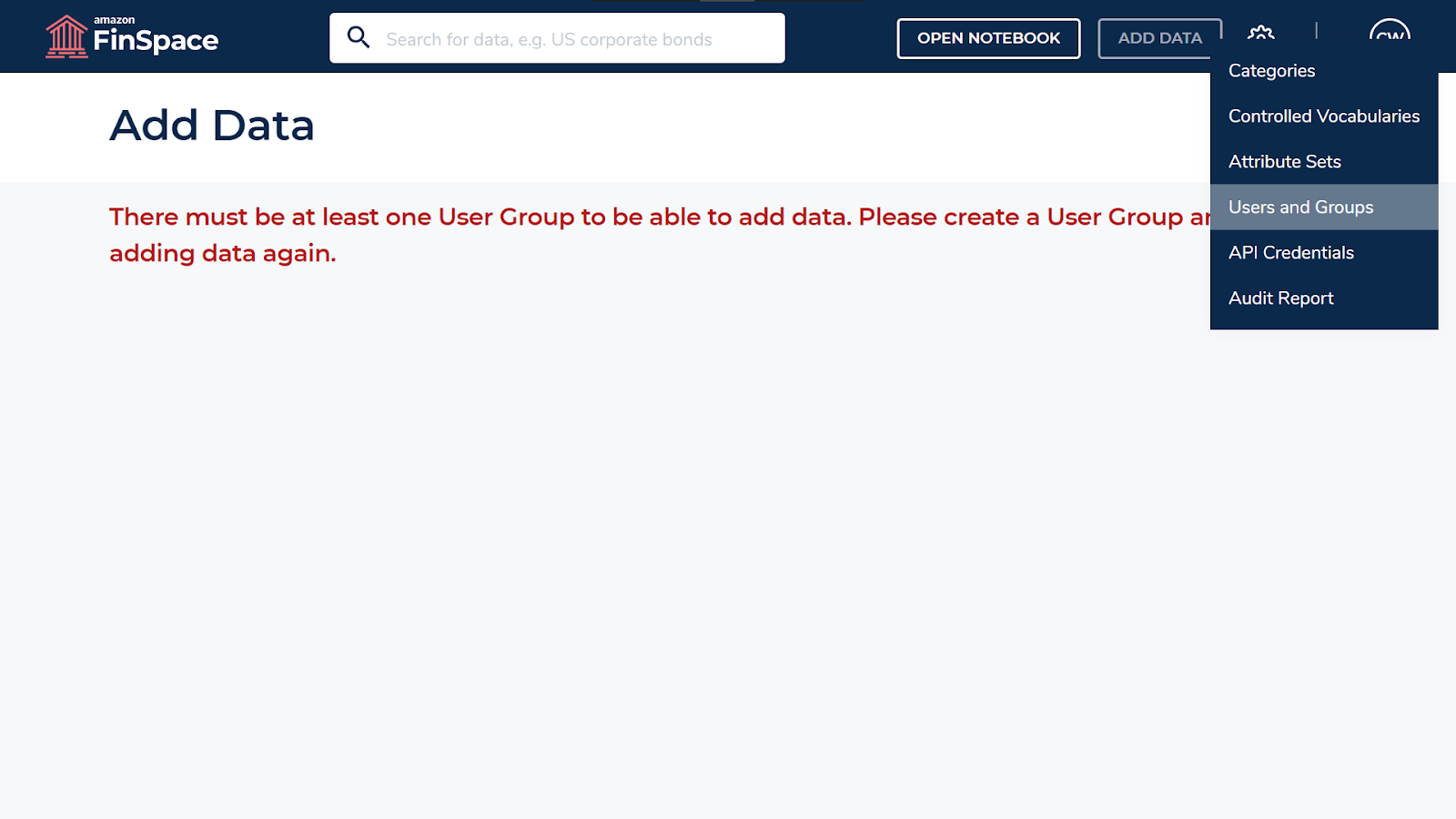
Click on Create User Group to create a new user group,

Enter a Group Name and a description as required. Select the permissions you want to allow for your user group.

Scroll down and click on Create.

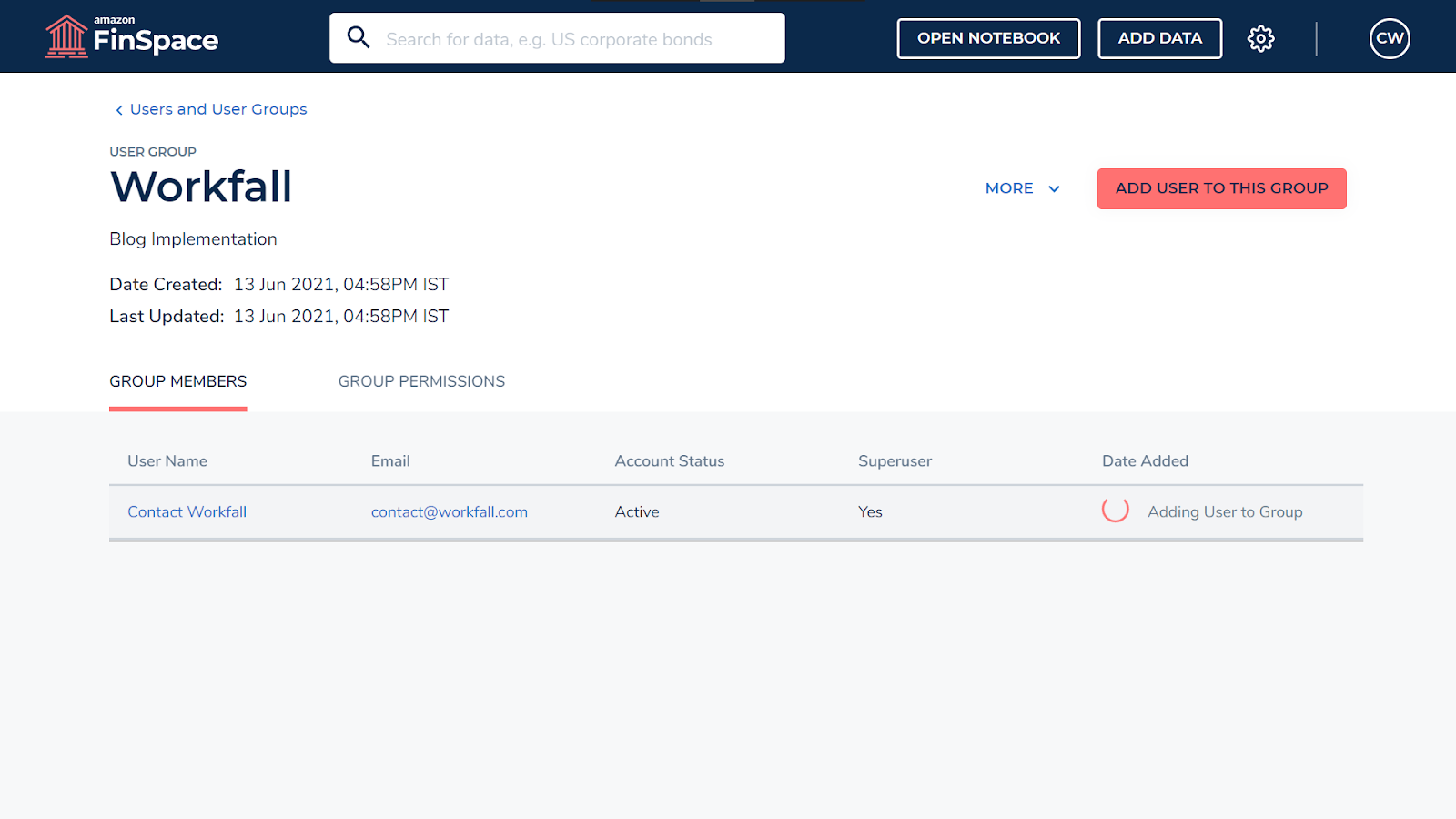
Add the user that’s created to the user group to give the user the required permissions.

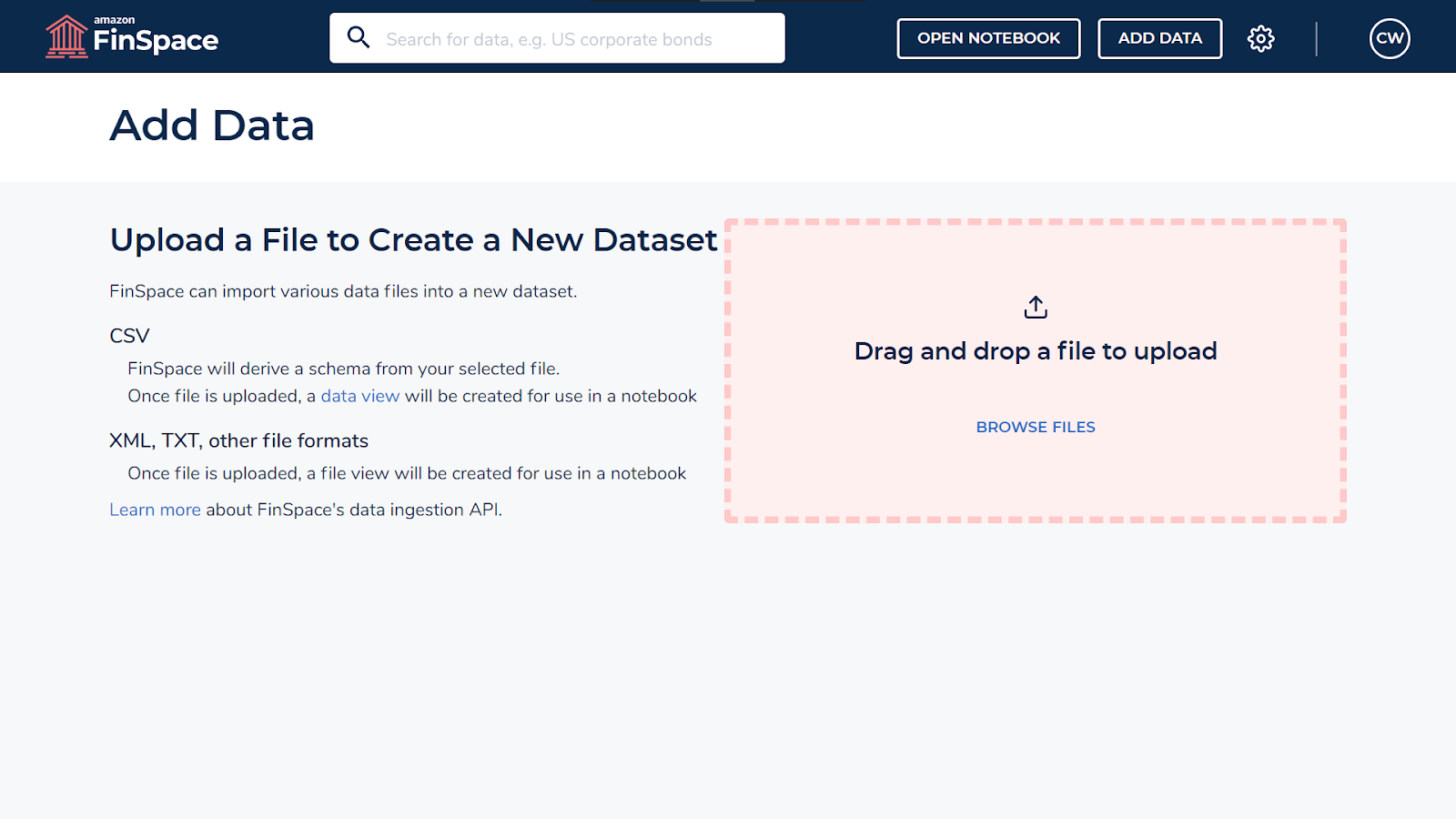
It might take some time for the new user group to be created. On completion, click on Add Data.
Select the csv (or any other file format) of your dataset from your local machine.
Select the created user group from the dropdown.
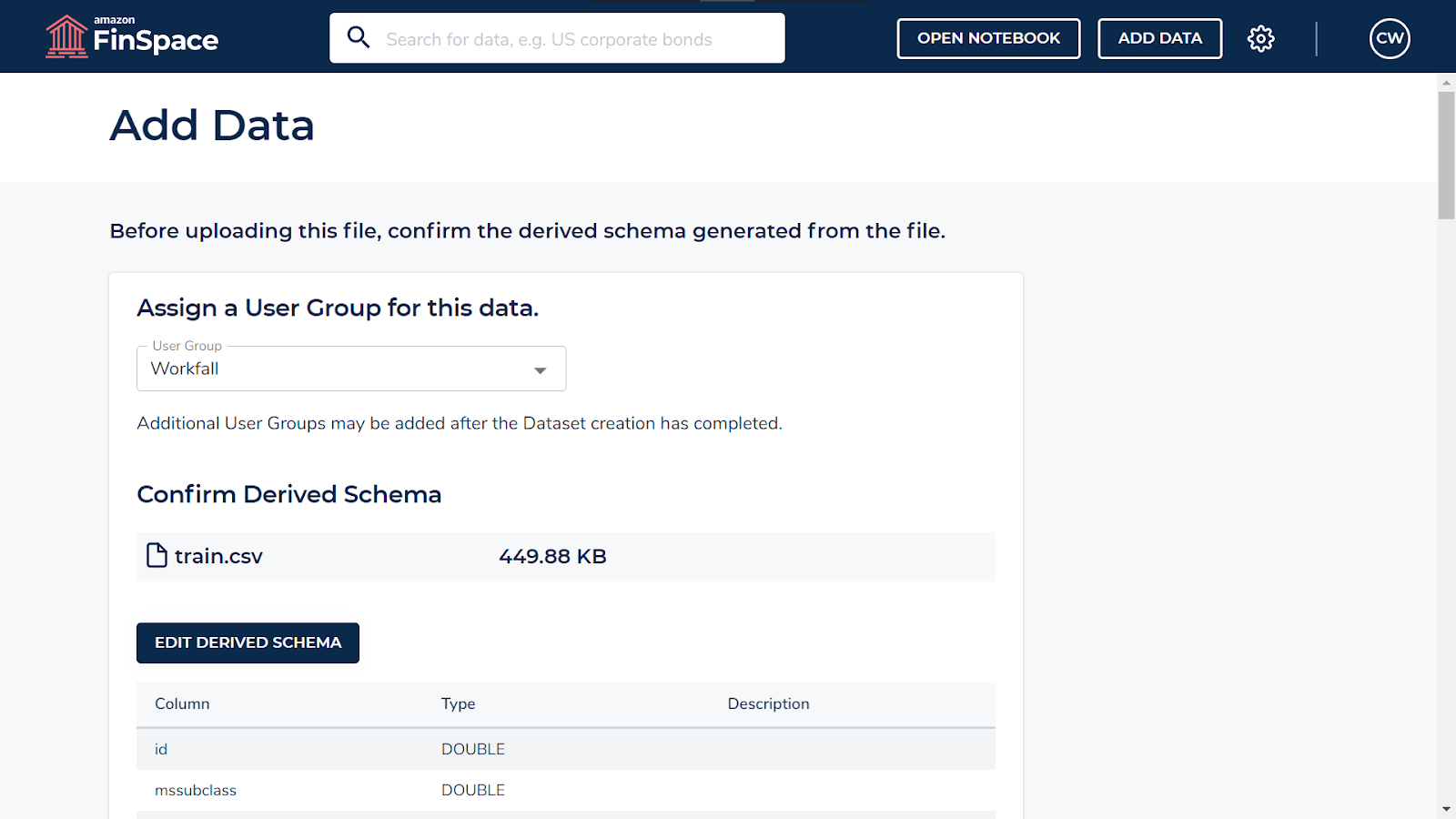
Edit the schema for your dataset if needed and if not, then you can proceed with the default settings.

Scroll down and click on confirm schema and upload file.

It will take some time for the schema to be configured.
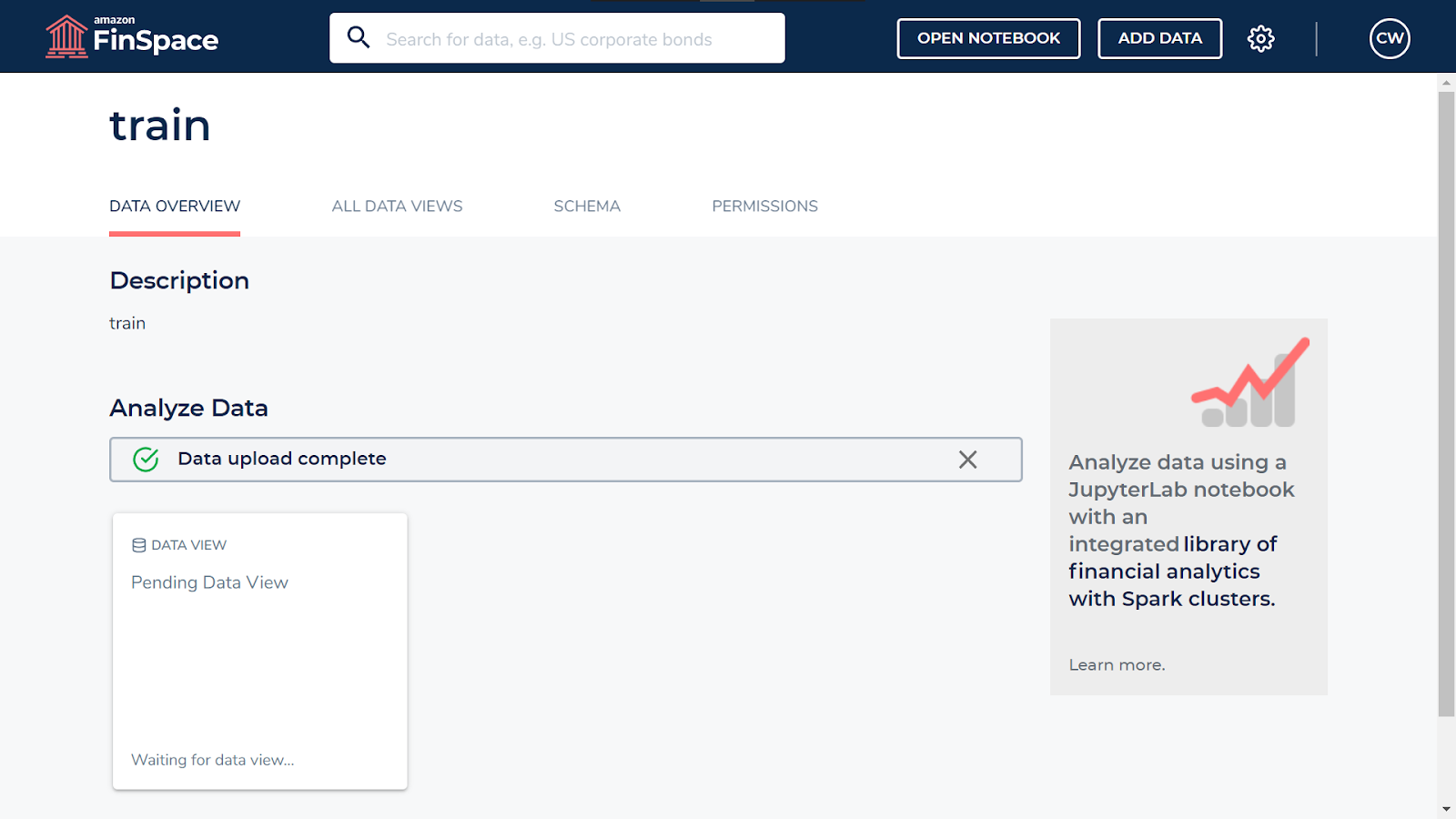
After a few seconds, you will get to see the creation date for your dataset.
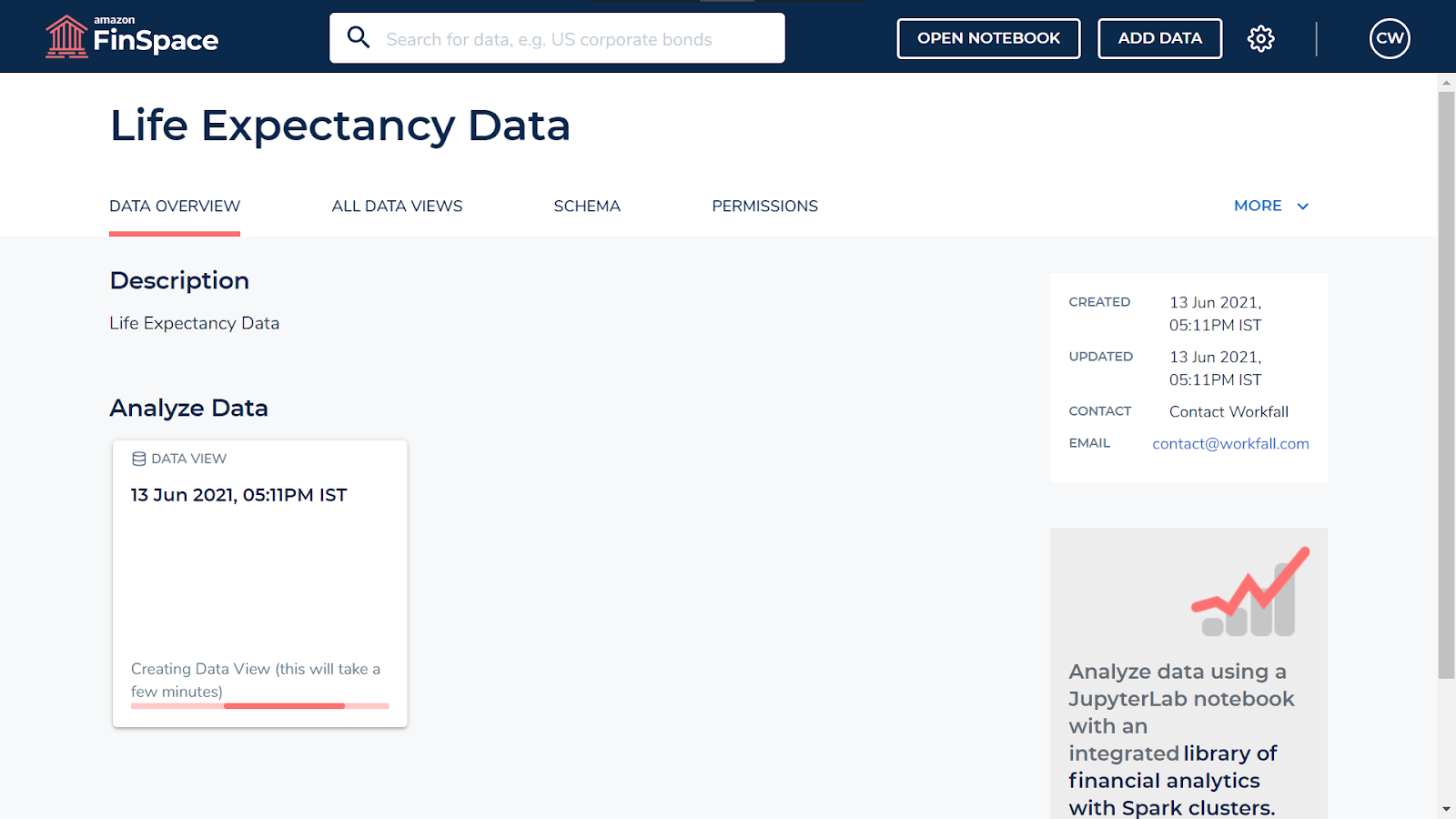
On completion, you will see the entry as shown in the image below.
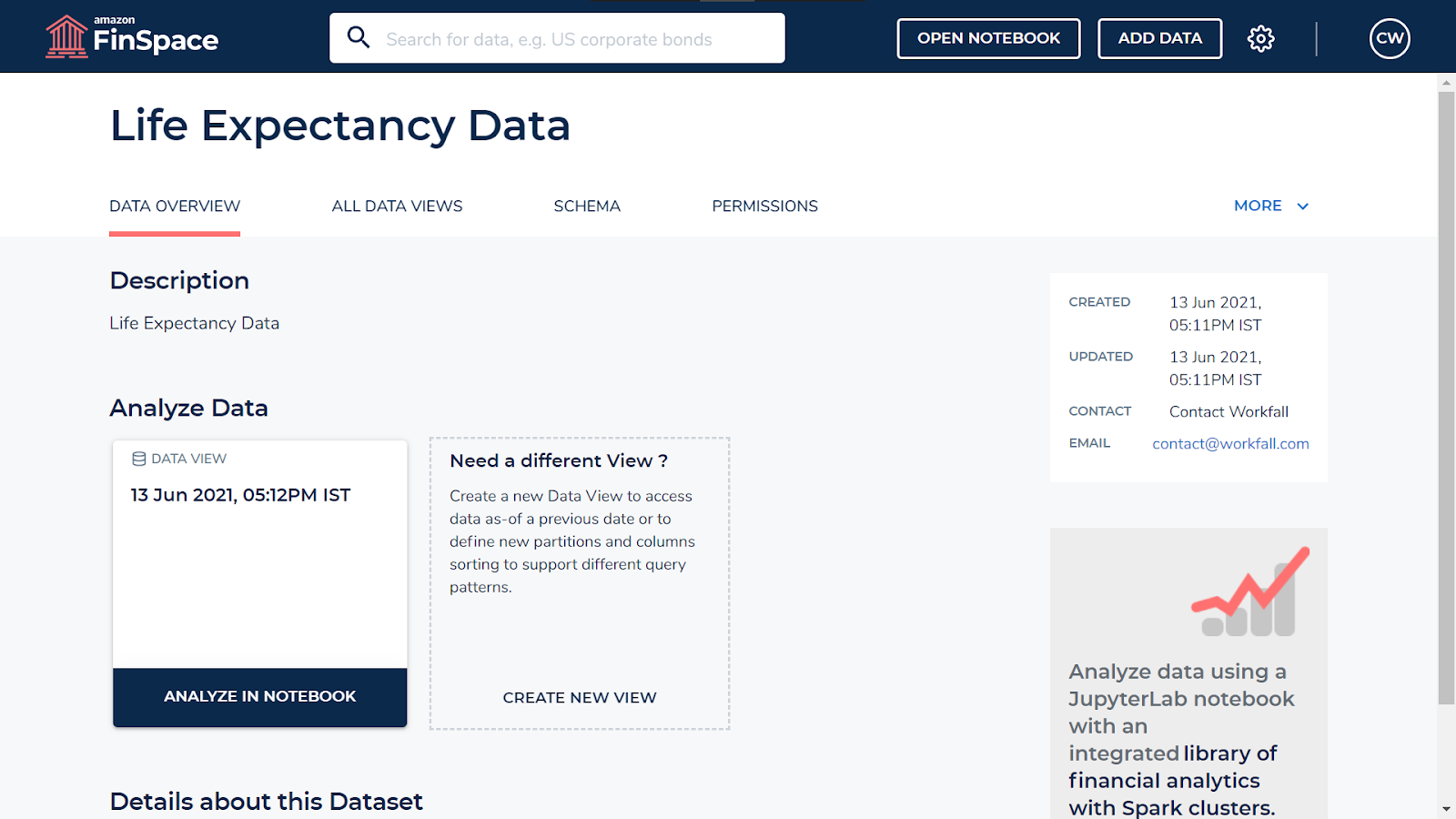
Click on All Data Views to view the details for your created schema.

Navigate back to Data Overview and click on Analyze in Notebook. Your Jupyter notebook will open up in the Amazon Sagemaker Studio.

You will see the Jupyter Notebook icon in some time on the screen.
You will be navigated to the screen as shown below.
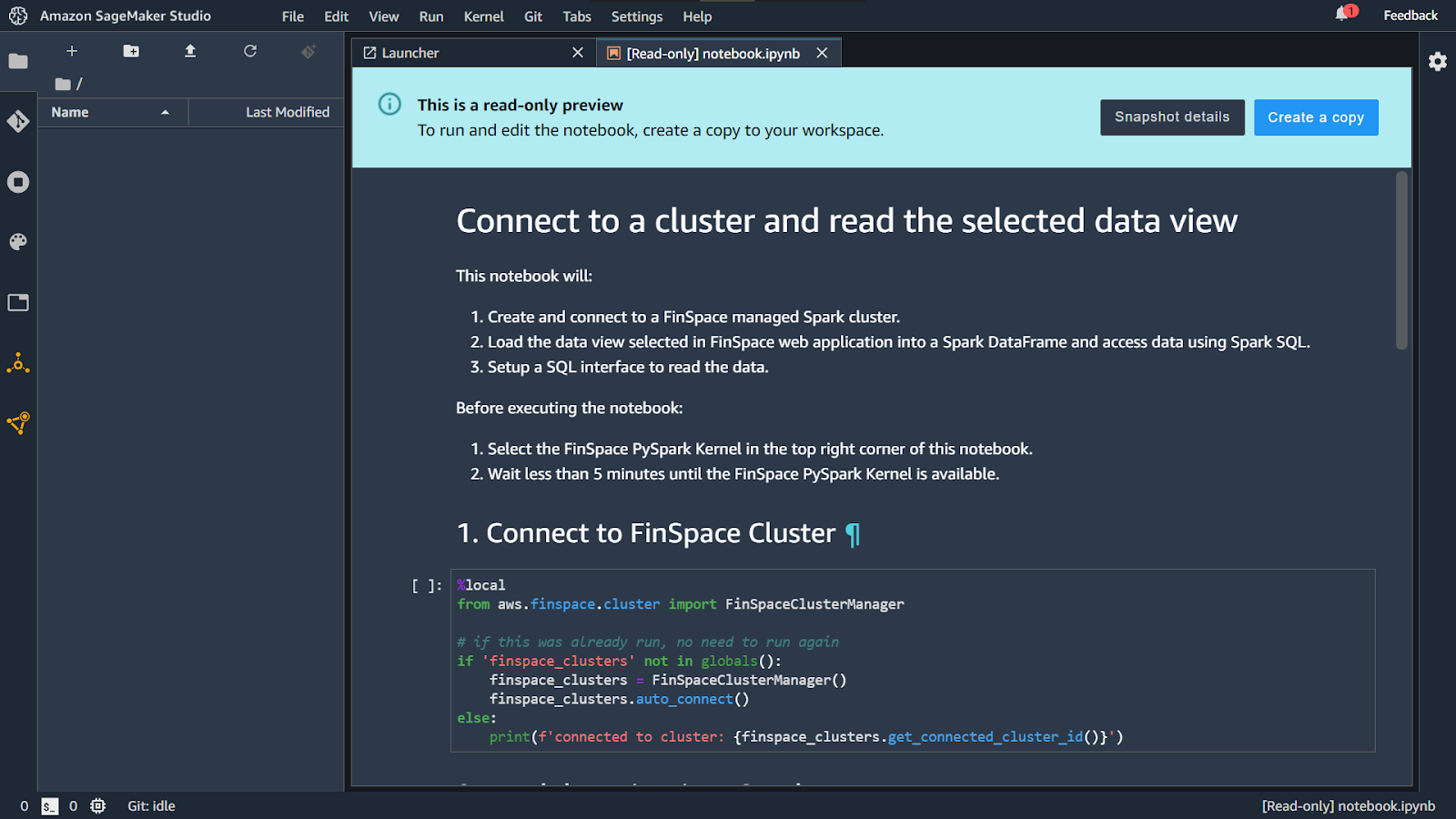
Click on Launcher in the opened tabs. Scroll down and click on the + icon besides Notebook.

Click on the Python 3 (Data Science) to select a server.

A modal will open up. Click on the dropdown.
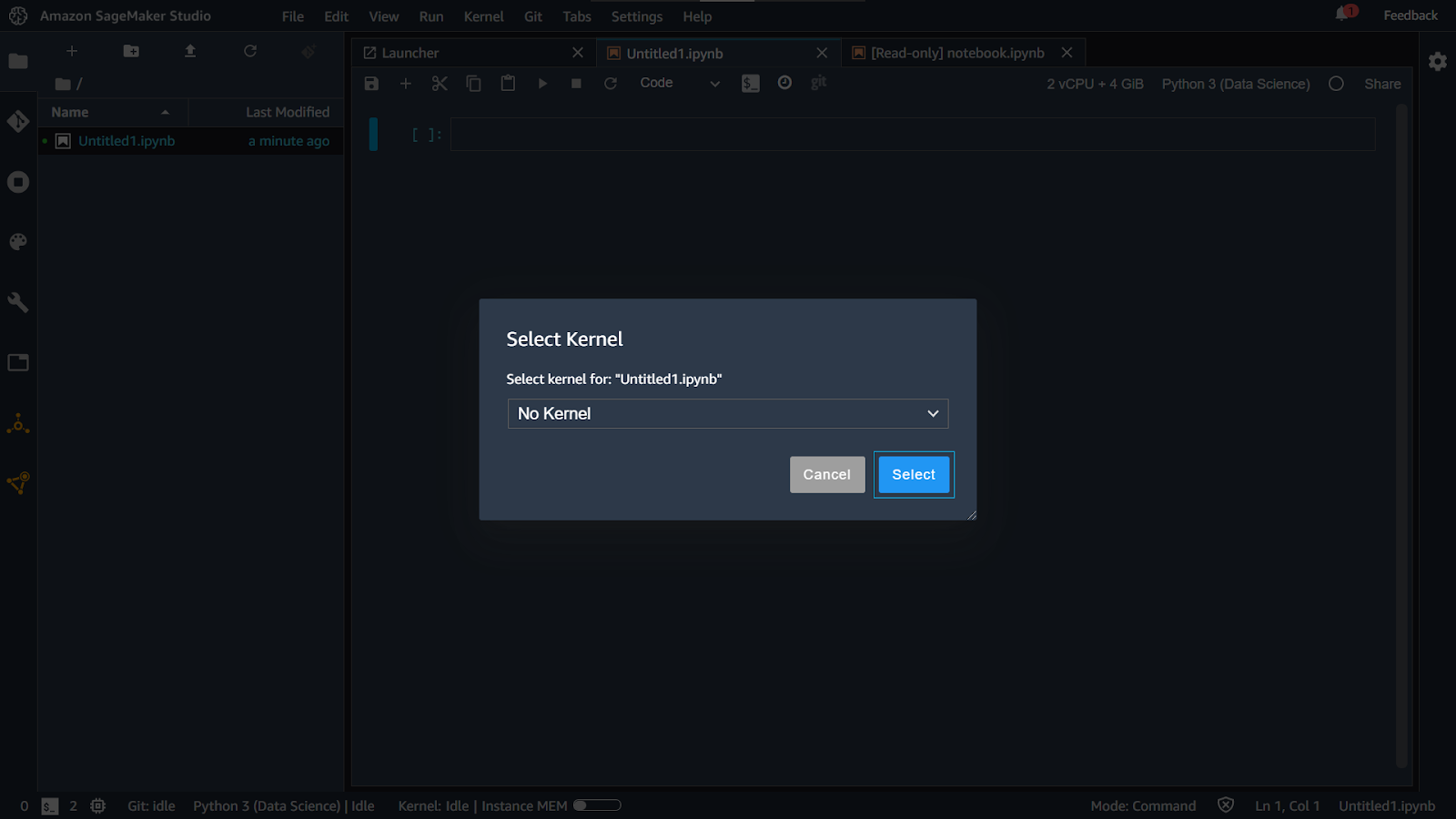
Select the FinSpace PySpark server from the dropdown.

You will see the new server selected for your notebook.
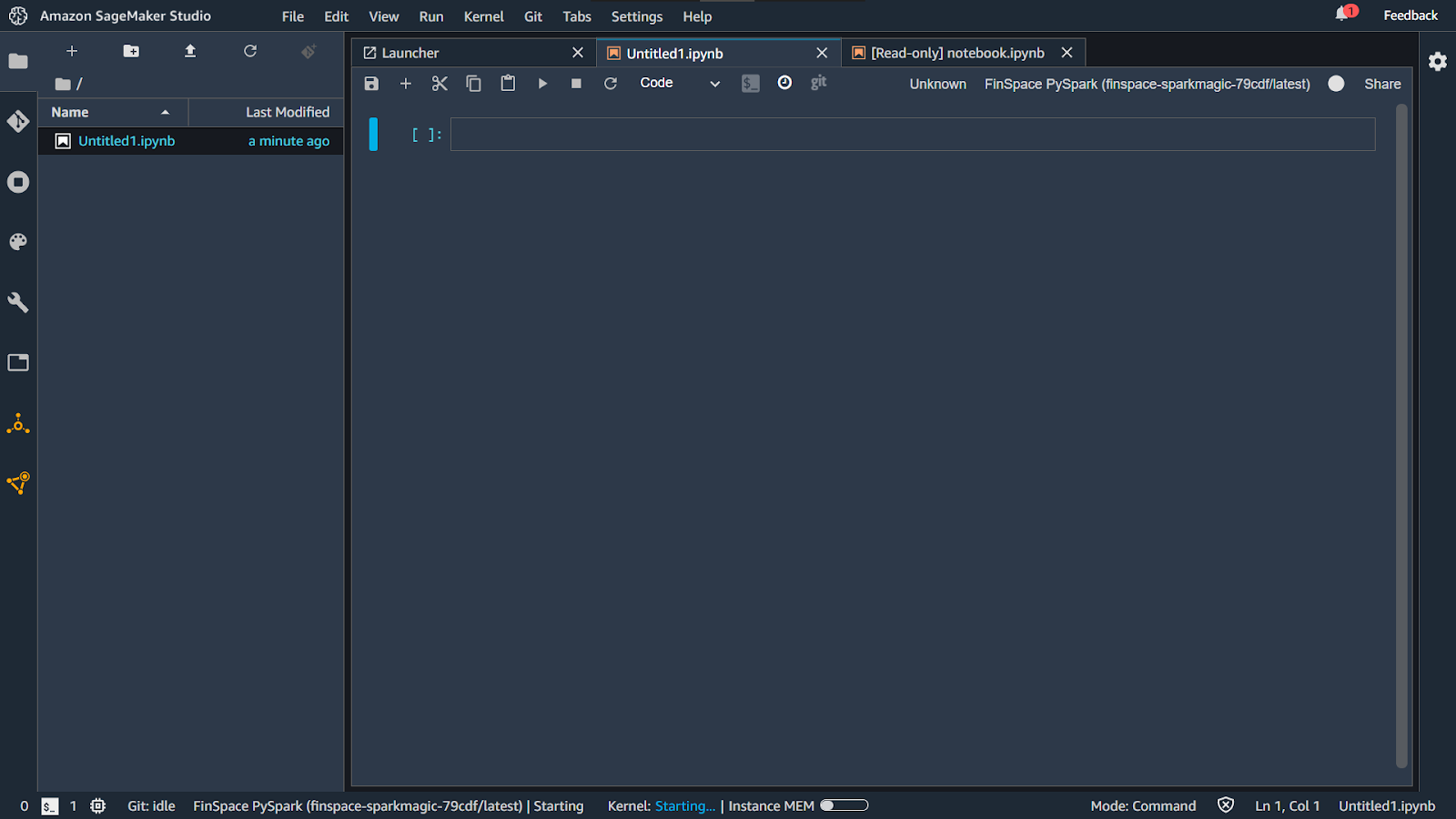
Copy the first section of the code as shown in the image below.
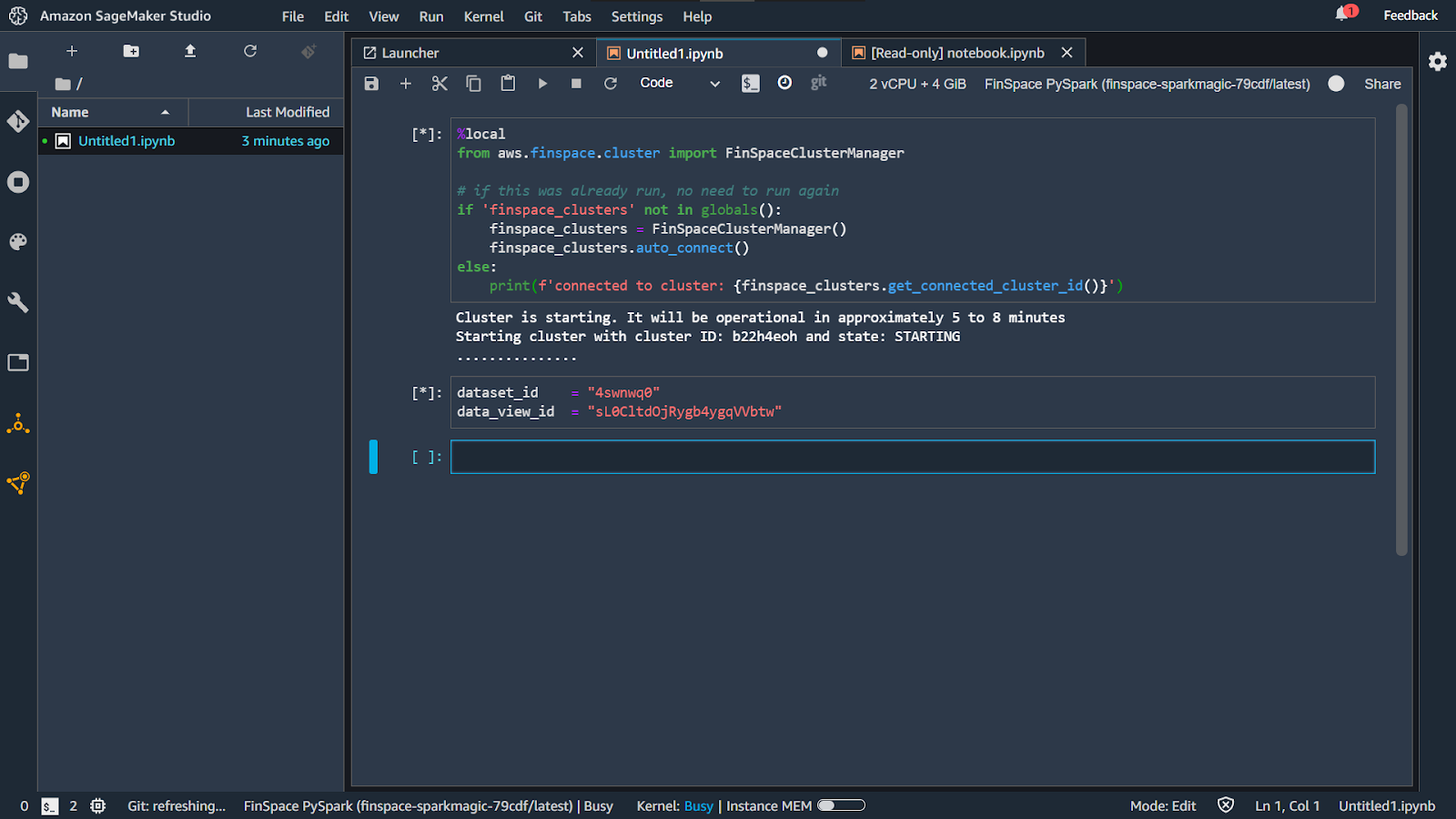
Navigate to your Notebook instance and paste the code. Click on Play or ALT + Enter to execute the code.

You will see a message stating your cluster is starting. This might take a few minutes to be configured.

Section wise, add the other part of the code and click on Play.
Now use the below code in the next section to connect to your dataset so that you can access your dataset.

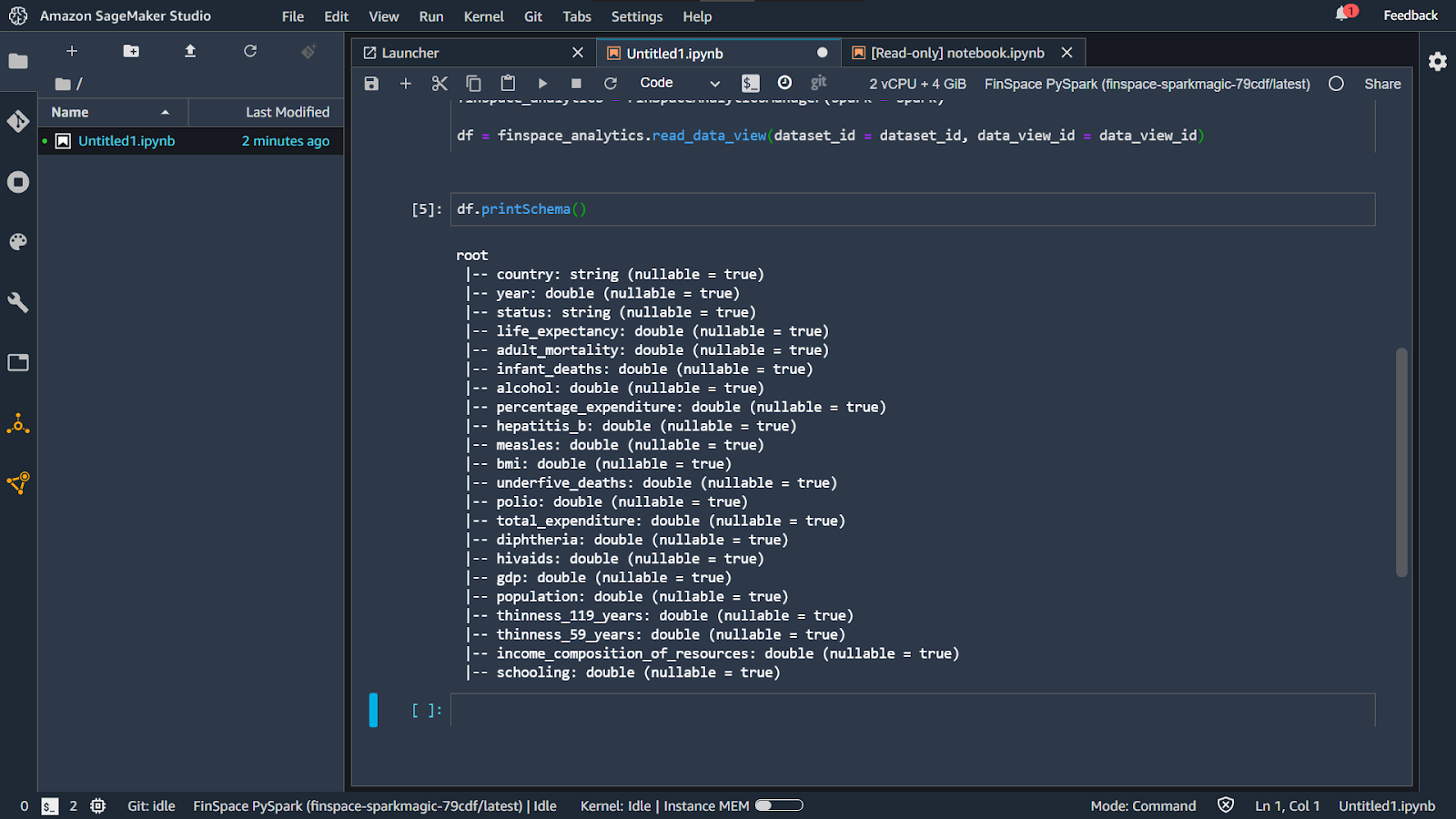
To print the schema for your dataset, you can enter the below code in the next section and click on Play.

Now wait for a few minutes and let the cluster be created and started. Once done, you will start seeing the output for each of the sections.

If you scroll down, you will see the schema for your dataset on your notebook instance.
To view the data in the dataset, enter the command as shown in the image below.

To view the head of your data in the dataset, use the command in the image below. Now, since you have the data, you can easily perform your data cleansing, analysis, and prediction processes as per your requirements and operate the same like operating a normal Jupyter Notebook.

Conclusion
In this blog, we have seen how to create and make use of the Amazon FinSpace environment to simplify the process of Data Management and Analytics for prediction models.
We have explored the FinSpace dashboard by creating a new User Group, adding users to the user group, attaching multiple permissions, and thus, adding a new dataset.
Finally, after attaching the required permissions and defining the schema for your dataset, we then performed analysis for the dataset in Jupyter Notebook on the Amazon SageMaker Studio console by integrating the FinSpace environment to the Amazon SageMaker Studio console and thereby accessing the data from the dataset for further analysis.
We will discuss more use cases of Amazon FinSpace in our upcoming blogs. Stay tuned to keep getting all updates about our upcoming new blogs on AWS and relevant technologies.
Meanwhile …
Keep Exploring -> Keep Learning -> Keep Mastering
This blog is part of our effort towards building a knowledgeable and kick-ass tech community. At Workfall, we strive to provide the best tech and pay opportunities to AWS-certified talents. If you’re looking to work with global clients, build kick-ass products while making big bucks doing so, give it a shot at workfall.com/partner today.


